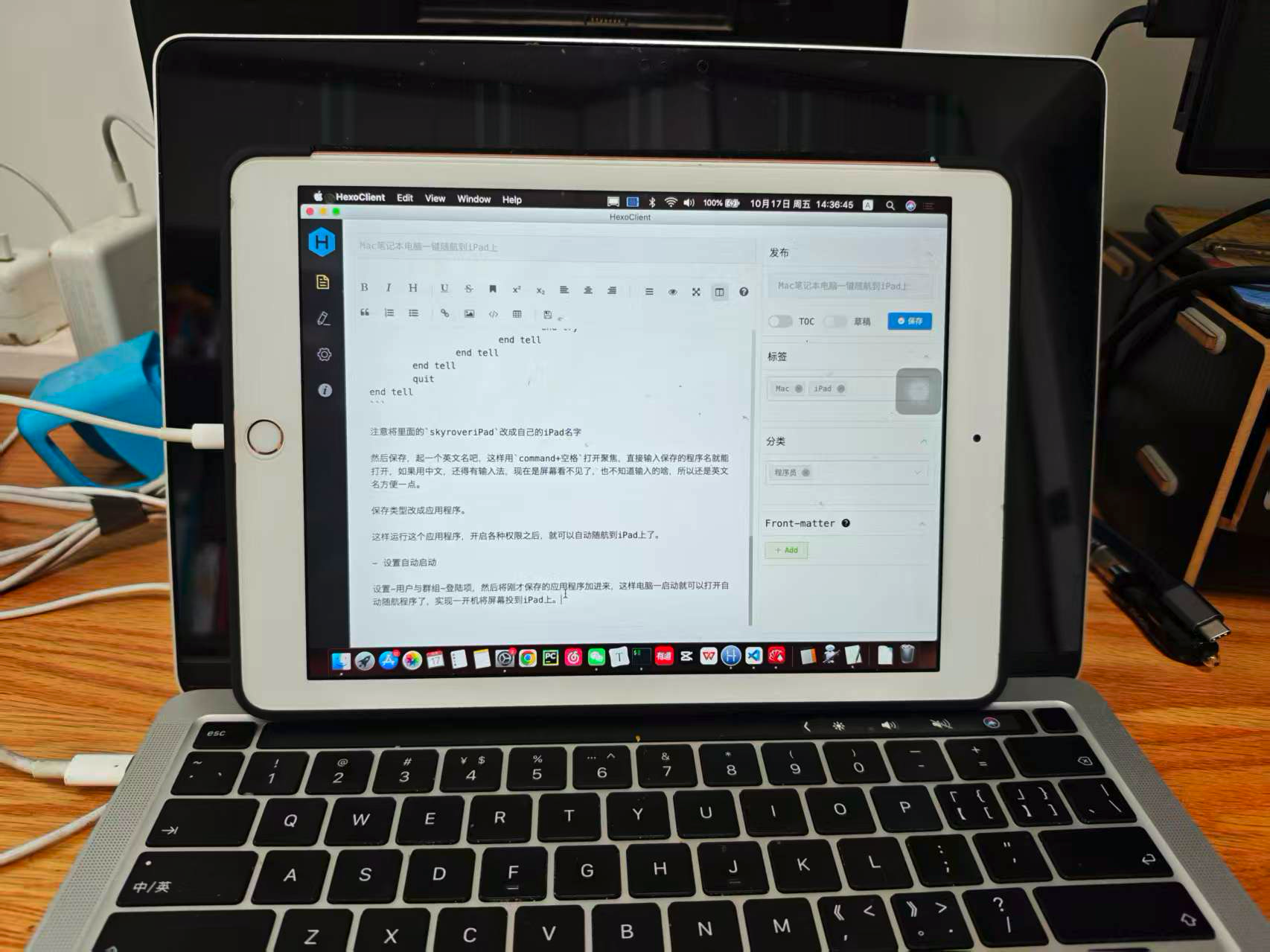
tell application "System Preferences" activate delay 0.5 set the current pane to pane id "com.apple.preference.sidecar" beep 1 delay 2 tell application "System Events" tell application process "System Preferences" tell window "随航" try click menu button "无设备" say "There is no iPad, please wait for seconds" delay 5 end try try click button "断开连接" say "Try again" delay 5 end try try click menu button "选择设备" say "iPad connecting" click menu item "skyroveriPad" of menu "选择设备" of menu button "选择设备" of window "随航" of application process "System Preferences" of application "System Events" --将403 Forbidden改成你的iPad的名字 end try end tell end tell end tell quit end tell
然后在docker-compose配置文件所在目录运行:docker-compose up -d就可以运行了。
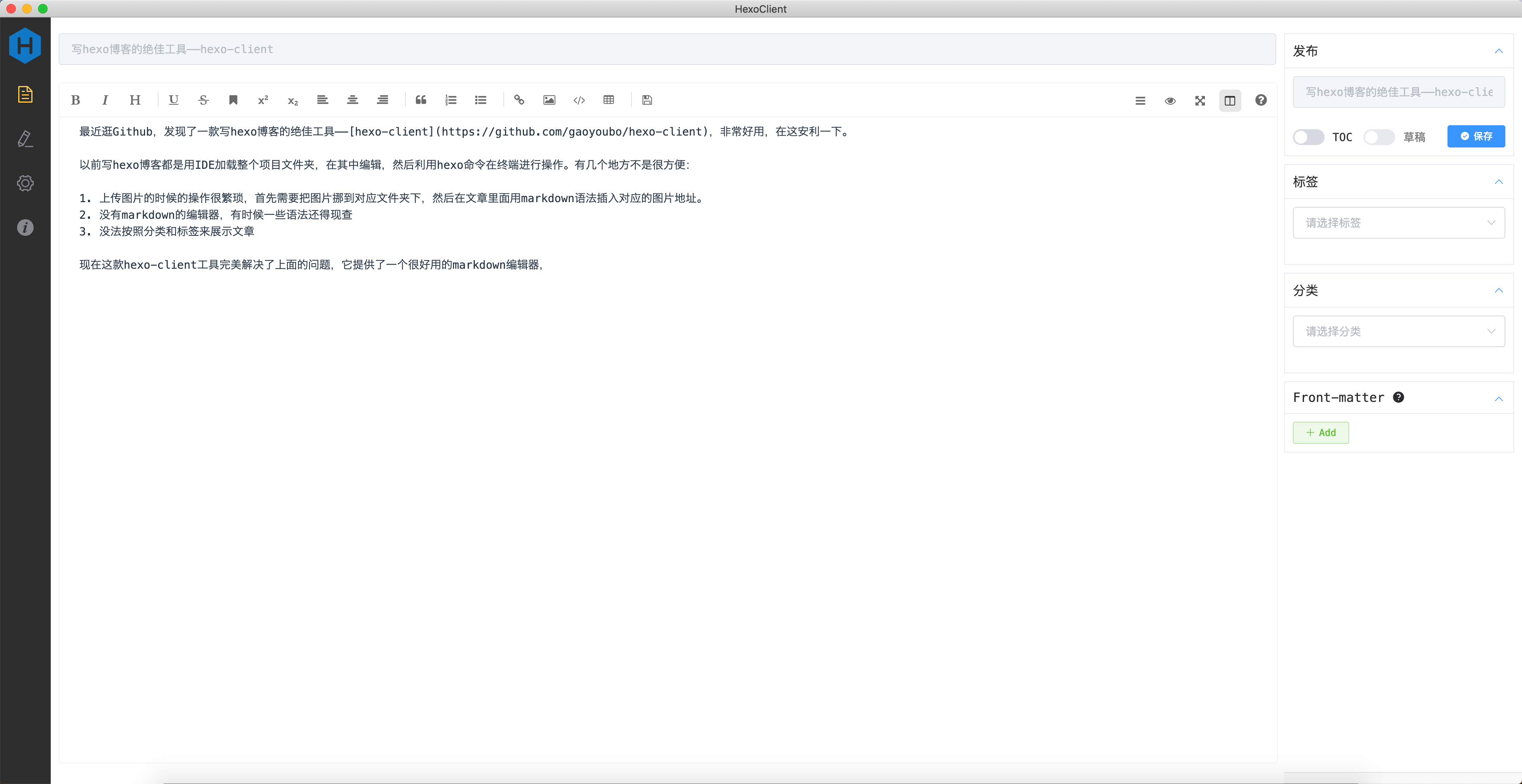
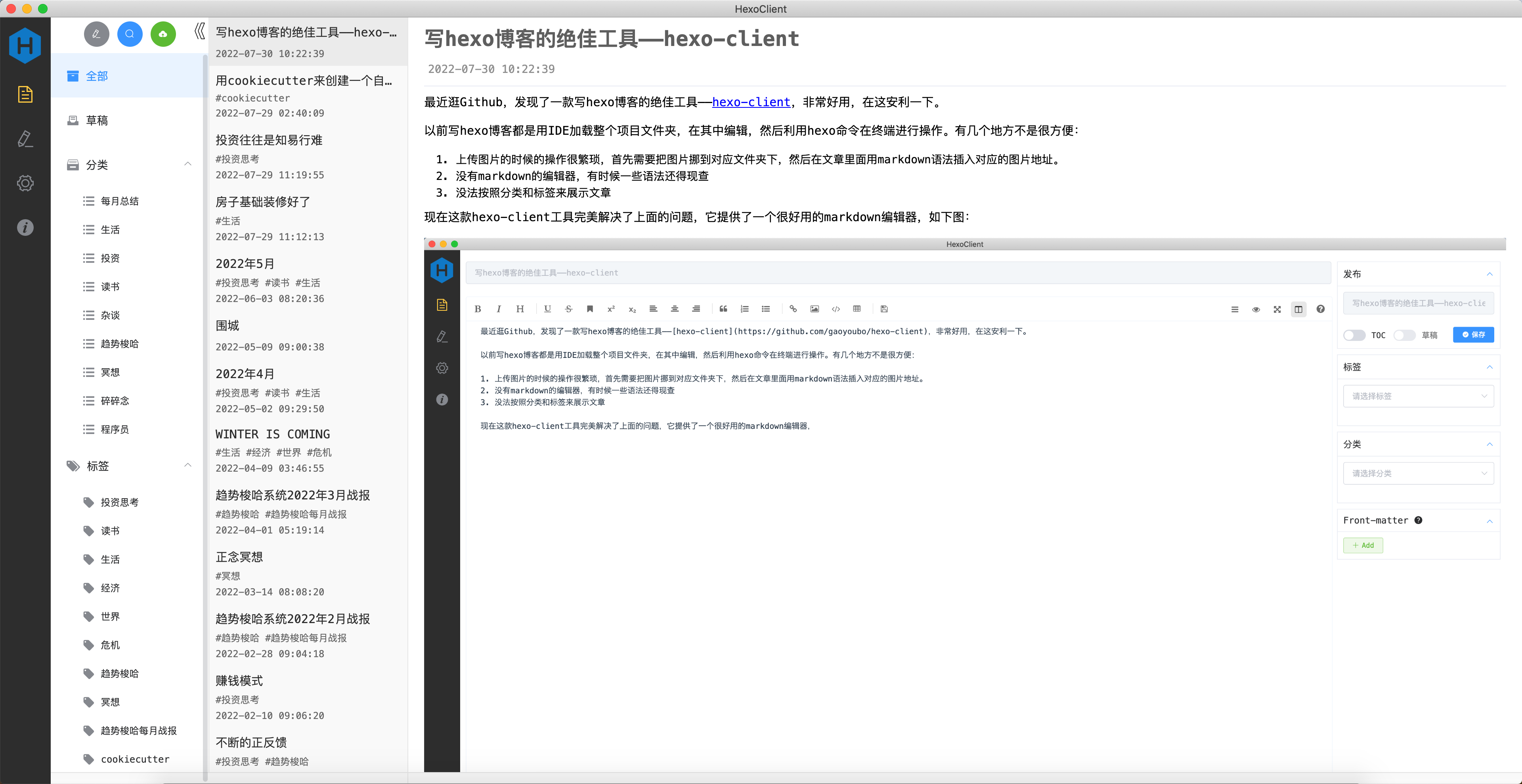
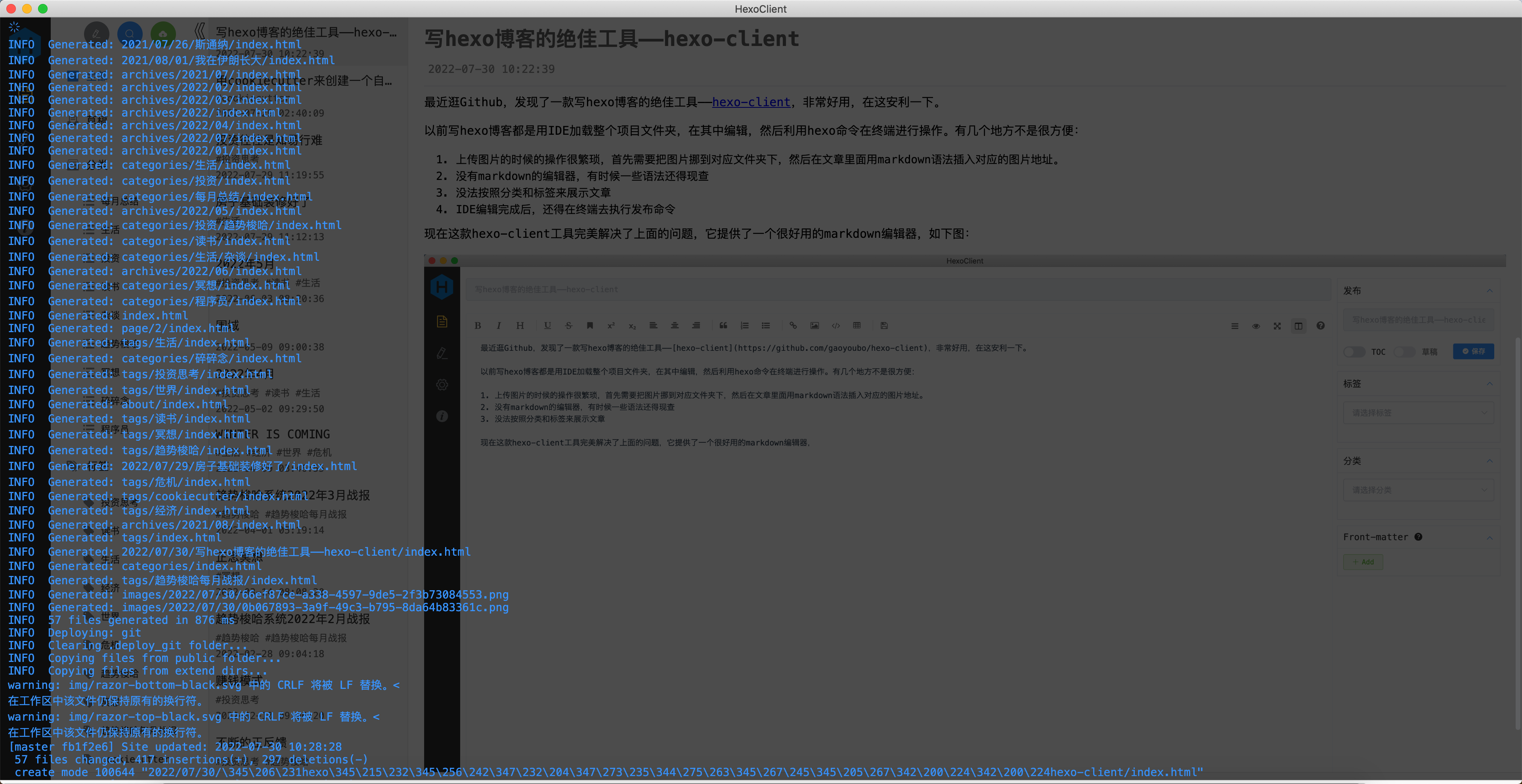
配置
更改Volumes配置:
1 2 3 4
volumes: # "/host/folder:/photoprism/folder" # Example # - "~/Pictures:/photoprism/originals" # Original media files (DO NOT REMOVE) -"/home/skyroverb/nas-data/back-up-data/照片:/photoprism/originals"
# Create one instance, seeded from current time, and export its methods # as module-level functions. The functions share state across all uses #(both in the user's code and in the Python libraries), but that's fine # for most programs and is easier for the casual user than making them # instantiate their own Random() instance.
SELECT document.id, (COALESCE(CAST(document.internal_info->>'proofread_time'ASint), 0) - p500_end.end_utc) /60AS proofread_time FROM document JOIN p500_end ON p500_end.doc_id = document.id WHERE document.created_utc >1658592000AND document.deleted =0AND proofread_time >60 ORDERBY id DESC
但是发现报这样的错误:
ERROR: column "proofread_time" does not exist
然后我把 WHERE 条件里的 proofread_time 替换成 (COALESCE(CAST(document.internal_info->>'proofread_time' AS int), 0) - p500_end.end_utc) / 60,就正常了。
咦,好奇怪,难道 alias 不能在 WHERE 条件里用吗,有点反直觉,于是我去查了下文档:
An output column’s name can be used to refer to the column’s value in ORDER BY and GROUP BY clauses, but not in the WHERE or HAVING clauses; there you must write out the expression instead.
原因就是 WHERE 语句和 HAVING 语句是在 column aliases 之前做的,所以没法引用,而 ORDER BY 和 GROUP BY 是在其之后,所以可以使用 aliased column
很古怪吧,反直觉!
但是把这么一长串的表达式写两遍真的很难受,所以我使用了 WITH 表达式来解决这个问题:
1 2 3 4 5 6 7 8
WITH results AS ( SELECT document.id, (COALESCE(CAST(document.internal_info->>'proofread_time'asint), 0) - p500_end.end_utc) /60AS proofread_time FROM document JOIN p500_end ON p500_end.doc_id = document.id WHERE document.created_utc >1658592000AND document.deleted =0 ORDERBY id DESC ) SELECT id, proofread_time FROM results WHERE proofread_time >60;
@classmethod defget_start_node(cls, formula_dict): for key, value in formula_dict.items(): if value.data['origin']['name'] == '=': left_node = formula_dict.get(value.data['origin']['left']) right_node = formula_dict.get(value.data['origin']['right']) return left_node if left_node.data['origin'].get('operator') else right_node returnNone
defprocess(self): if self.expression and'('notin self.expression: return # 搜索 left 和 right 的最低优先级 X,Y, # 如果 X 优先级小于 start_node 的优先级,那么 X 需要括号 # 否则,不需要括号 # 对于 Y 同理 # 只在一个分支上检查level # 特例 / - 右边分支如果有同级的 需要带括号 # 括号内部 非括号部分的优先级 self.fill_node_bracket(self.start_node)
defensure_bracket(self, child_bracket): ifnot child_bracket: return self.small_bracket child_bracket_order = self.brackets[child_bracket] for bracket, order in self.brackets.items(): if order > child_bracket_order: return bracket returnNone
deffind_child_bracket(self, node): ifnot node: return bracket = node.data['origin'].get('bracket') if node.data['origin']['left'] != -1: left_bracket = self.find_child_bracket(self.formula_dict.get(node.data['origin']['left'])) if left_bracket: ifnot bracket: bracket = left_bracket else: bracket = left_bracket if self.brackets[left_bracket] > self.brackets[bracket] else bracket if node.data['origin']['right'] != -1: right_bracket = self.find_child_bracket(self.formula_dict.get(node.data['origin']['right'])) if right_bracket: ifnot bracket: bracket = right_bracket else: bracket = right_bracket if self.brackets[right_bracket] > self.brackets[bracket] else bracket return bracket
SELECT "user".id as user_id, "user".username as user_name, (SELECTcount(project.id) AS cnt FROM project WHERE project.user_id = "user".id AND project.deleted =0) AS user_projects_cnt, coalesce((SELECT user_login_info.created_utc FROM user_login_info WHERE user_login_info.user_id = "user".id ORDERBY user_login_info.id DESC LIMIT 1), "user".id) AS default_login_time FROM "user" WHERE "user".deleted =0ORDERBY default_login_time DESC, "user".ext_id DESC LIMIT 10OFFSET0
Sort (cost=750000347885.10..750000347885.29 rows=75 width=566) Sort Key: ((SubPlan 2)) DESC, "user".id DESC -> Bitmap Heap Scan on "user" (cost=8.75..750000347882.77 rows=75 width=566) Recheck Cond: (ext_sys = 1) Filter: (deleted = 0) -> Bitmap Index Scan on idx_user_ext_sys (cost=0.00..8.73 rows=78 width=0) Index Cond: (ext_sys = 1) SubPlan 1 -> Aggregate (cost=19.27..19.28 rows=1 width=8) -> Bitmap Heap Scan on document (cost=4.21..19.25 rows=5 width=4) Recheck Cond: (user_id = "user".ext_id) Filter: ((user_sys = 1) AND (deleted = 0)) -> Bitmap Index Scan on idx_user_id (cost=0.00..4.21 rows=8 width=0) Index Cond: (user_id = "user".ext_id) SubPlan 2 -> Limit (cost=10000004618.93..10000004618.94 rows=1 width=4) -> Sort (cost=10000004618.93..10000005141.43 rows=209000 width=4) Sort Key: user_login_info.created_utc DESC -> Nested Loop (cost=10000000000.15..10000003573.93 rows=209000 width=4) -> Seq Scan on user_login_info (cost=10000000000.00..10000000942.95 rows=1045 width=4) Filter: (user_id = "user".id) -> Materialize (cost=0.15..18.98 rows=200 width=0) -> Index Only Scan using idx_document_user_sys on document document_1 (cost=0.15..17.98 rows=200 width=$ ) Index Cond: (user_sys = 1)
Planning time: 0.212 ms Execution time: 229.674 ms
解决
那么现在首要问题就是如何避免子查询,可以看到需求里是需要最近用户登录时间和用户的项目数,那么一个很自然的思路就是先把这两个数据查出来,然后再和 User Join到一起进行分页即可,这样就可以避免子查询嵌套到父查询里了,这里涉及到一个子查询的优化方法,尽量将关联子查询上推,上推到和父查询一个层级以避免 Nested Loop。
WITH user_projects_query AS (SELECT project.user_id AS user_id, count(project.id) AS cnt FROM project WHERE project.deleted =0GROUPBY document.user_id ), login_utc_query AS (SELECT user_login_info.user_id AS user_id, max(user_login_info.created_utc) AS login_utc FROM user_login_info GROUPBY user_login_info.user_id ) SELECT "user".id AS user_id, "user".username AS username, user_projects_query.cnt AS user_projects_query_cnt, coalesce(login_utc_query.login_utc, "user".created_utc) AS login_utc FROM "user" LEFTOUTERJOIN user_projects_query ON user_projects_query.user_id = "user".id LEFTOUTERJOIN login_utc_query ON login_utc_query.user_id = "user".id WHERE "user".deleted =0 ORDERBY login_utc DESC, "user".ext_id DESC LIMIT 20OFFSET0
# make sure all the fields are included assert'name="username"'in html assert'name="email"'in html assert'name="password"'in html assert'name="password2"'in html assert'name="submit"'in html
这样的方式也适合于其他数据量比较大的测试,只需要测试关键部分即可。
提交表单
主要问题在于 CSRF token 怎么处理,可以先发一个 GET 请求,然后拿到 token,再去提交表单,这是一种方法。另一种方法就是在测试中禁掉 CSRF 的保护。
1 2 3 4 5 6 7
defsetUp(self): self.app = create_app() self.app.config['WTF_CSRF_ENABLED'] = False# no CSRF during tests self.appctx = self.app.app_context() self.appctx.push() db.create_all() self.client = self.app.test_client()
测试表单验证
根据表单验证失败返回的语句进行判断
1 2 3 4 5 6 7 8 9 10
deftest_register_user_mismatched_passwords(self): response = self.client.post('/auth/register', data={ 'username': 'alice', 'email': 'alice@example.com', 'password': 'foo', 'password2': 'bar', }) assert response.status_code == 200 html = response.get_data(as_text=True) assert'Field must be equal to password.'in html
# make sure the user is in the database user = User.query.filter_by(username='bob').first() assert user isnotNone assert user.email == 'bob@example.com'
defsave_user(self, user_data): user = User.make_user(uid=user_data['id'], ext_uname=user_data['name'], username=user_data['name'], _from='casdoor') return user