车水马龙才是国泰民安
楼下的街道一片萧瑟,偶尔会有几辆车经过,行人基本上见不到,因为都已经静默在家了。

有句话说的好啊:车水马龙才是国泰民安,什么时候能恢复往日的热闹,什么时候这个国家才算正常。
新冠疫情三年,现在愈演愈烈,并不是说病毒变得更厉害,而是现在有一种态势:为了防疫而防疫,除了新冠,其他都不是病
这很可怕,因为其中就会产生各种病态,疯狂
我们能做点什么呢,除了照顾好自己的家人之外什么也做不了
楼下的街道一片萧瑟,偶尔会有几辆车经过,行人基本上见不到,因为都已经静默在家了。
有句话说的好啊:车水马龙才是国泰民安,什么时候能恢复往日的热闹,什么时候这个国家才算正常。
新冠疫情三年,现在愈演愈烈,并不是说病毒变得更厉害,而是现在有一种态势:为了防疫而防疫,除了新冠,其他都不是病
这很可怕,因为其中就会产生各种病态,疯狂
我们能做点什么呢,除了照顾好自己的家人之外什么也做不了
这个月真的是太难了,FIRE 基金回测截止今天已经亏损 0.7% 了,而 FIRE 基金由于月初使用半仓格局了一把,现在还有快 3 个点的收益,但是也扛不住大幅回撤了。
哎。。。
鉴于目前行情的这种情况,而且也快到年底了,FIRE 基金准备开始逐渐分红,分红出来的资金一部分补充生活所需,一部分打算投入到 FIRE 基金养老版 中进行抄底。
分红策略就是固定一个资金额,每个月末只要比这个资金多,就分红,分红数额就是多余的部分。如果少于这个资金额,那就等超过的那个月末再分红吧。
截至目前还有 3 个点的收益额可以进行分红。
目前还在车上,满仓创业板,唉,生死有命,富贵在天。
就这样吧~
P.S. 目前 FIRE 基金已经有了两项比较重要的调整了:
创业板50 ETF,创成长 ETF,双创 ETF,上证50 ETF,科创50 ETF每月分红改为,每次上车之后只要有盈利以及大于固定资金额就进行分红。
真正的个人成长应该超越你自身存在问题且需要保护的那部分。
一个人内心的成长完全取决于他能否认识到,获得平静和满足的唯一途径就是停止考虑自己。
必须要打破一种思维习惯,即认为解决问题的办法在于重新安排外部事物,要永久性的解决你的问题,唯一的办法就是深入你的内心,让似乎总是与现实格格不入的那一部分的你得到解脱。
看了第二部分 体验能量,感触良多
的确,我从小就是一个比较封闭内心的人,记得小时候如果我觉得不高兴,不开心,我就会把自己锁到一个房间里,关闭门窗,任谁来叫我都不开门,我就呆在这个房子里,一呆好几个小时。
到了后来上班,当有人走到我跟前,我就神经紧张,这也是封闭内心的表现。
所以我非常疲惫,非常累,就是因为我把能量都用来保护自己了。
书中写道,如果你一味的保护自己,你将永远不会自由。
如果你关闭了自己,你就会把这个恐惧而没有安全感的你锁在自己的心里。这样做,你将永远不会自由。
最开始是在去年11月开始读这本书的,但是中途断了,这次辞职在家就开始读书,不到一个星期,就读完了,受益匪浅。
而且这本书里阐述的观点和我以前看到有些东西也是有异曲同工之妙,比如之前的文章:人生的松弛感
这篇文章就是说不论遇到什么事,都要保持松弛,没有什么大不了的。这就和书中的所说要做一个观察者,让思想能量从内心流过,而不是阻碍它,要放手一个意思。
这本书最后一章还提到了道德经,这让我感到惊喜,果然智慧都是互通的。我爸现在就在研究这些,没事还会跟我聊一聊道德经,有时间我也得去读一读。
清醒地活:放手,让一切经过你,不管是想法还是情绪。以高度觉知为基础,不做抵抗,开放内心,常常放手,以此走上超越自我的生命之旅。
很好的一本书,值得一读。
宝宝 18 周了,媳妇说能感受到宝宝胎动了,真的有点神奇啊。
但是在期待的情绪之外,还有一点点担心,担心能不能好好照顾媳妇和宝宝,能不能教育好宝宝,能不能做一个好爸爸。
离十字路口越来越近,很快就要作出决定了。
加油。

2021 年 1 月灵光乍现,开始构建交易系统,只做 ETF
1 月底初成,2 月初在上证 50 小试牛刀,赚了一把
随后 3 月市场大跌,也跟着亏损一波,然后收紧投资
此时心态还很稚嫩,当然主要还是缺乏盈利信心
根基还是交易系统没有完善
后来 4 到 6 月市场上涨,随即账户创新高,但是因为收紧投资,所以总收益并没有太多
在这段时间,也修复了不少系统 bug
是真 bug 的那种,数值计算错误的那种
随后 7 月市场开始震荡,又开始水土不服了
因为这时候还是人工确定什么时候该买入,什么时候卖出
具体什么时候,仍然不得其法,亏损扩大
一度让我有点放弃,甚至我已经转向买股票,又亏损一波
幸好坚持下来,在 7-10 月里积累数据和经验
10 月底确定了何时判断为强,何时判断为弱
也确定了买入和卖出的分时点
同时推出了程序自动决策功能
但是这仍然不能保证我稳定盈利
特别是 12 月初开始的这波下跌
又让我损失惨重
于是再次灵光一闪:止盈
在 2022 年 1 月份开发出了回测系统和止盈系统
确定出了最佳止盈参数,同时也优化了强弱判断策略
回测效果很 OK
2022 年 2 月年后,开始按此运行
果然最小回撤,稳定盈利
平稳度过 3,4 月份的股灾,
也没有错过 5,6 月份的反弹
4 个月收益率 20+%
于是我开始有点飘了
7,8 月份想快速赚一波,买股票,当然还是出于谨慎,买了银行和地产
那你知道的,保交楼,我又亏大了
9 月份啧啧,股灾又来了
这次虽然已经下决心坚持策略,只做 ETF
但是打野标的让我亏损严重
打野的都是行业标的,行业情绪化更严重,跌起来就不是人
虽然确实也能做,但是极端行情回撤就会很大
与我目前的目标相去甚远
10月痛定思痛,才明白多不一定是多,少才是多(less is more)
那目前交易系统只做这 5 个标的:创成长,创业板50,科创创业50,上证50,科创50
这几个回测都是往东北角走的,回撤也不大
同时也都是宽基,行业风险小,稳定
按照策略回测从2021年3月份到现在(不完全统计)
这5个收益率总计60%。。。
好了,现在战船已固,前方即是星辰大海!
11 月,现在策略,操作,资金,心态都已处于稳定期了
截至目前,11 月收益率已经快 5%,很稳
那么
乘风破浪会有时,直挂云帆济沧海~
之前一直用挖财记账,从大学开始,断断续续的记账,到现在差不多快 10 年了。是什么让我放弃挖财转向 beancount 了呢:
首先是为什么要记账,以我个人这快 10 年的记账经验来讲,记账可以让你更好的把控你的财务能力,在我断断续续记账的时间里,记账的时候对自己财务非常清晰,该怎么花钱,花多少钱心里都会有数;而不记账的时候,就感觉没有把控力,对自己财务也非常模糊,花钱花的也有点失控。
通过记账不仅可以加深对自己的财务的了解,也可以根据支出的数据针对性的进行优化。如果要达到财务自由,需要达到三点要求,对支出的预期,对资产和收入的了解,和对寿命的期望。而记账可以解决前两点。
当你开始记账,你就会发现自己离自己的财务自由目标就更近了。
试想一下,假设把你作为一家公司,如果对自己的财务状况和自己的财务能力都不了解,谈何发展?
嗯,大概就是这么些点,说服了我从挖财转向了 beancount。
昨晚上搞了一晚上,搞清楚了 beancount 怎么安装,怎么配置,最终搞好了自己的一套 beancount:
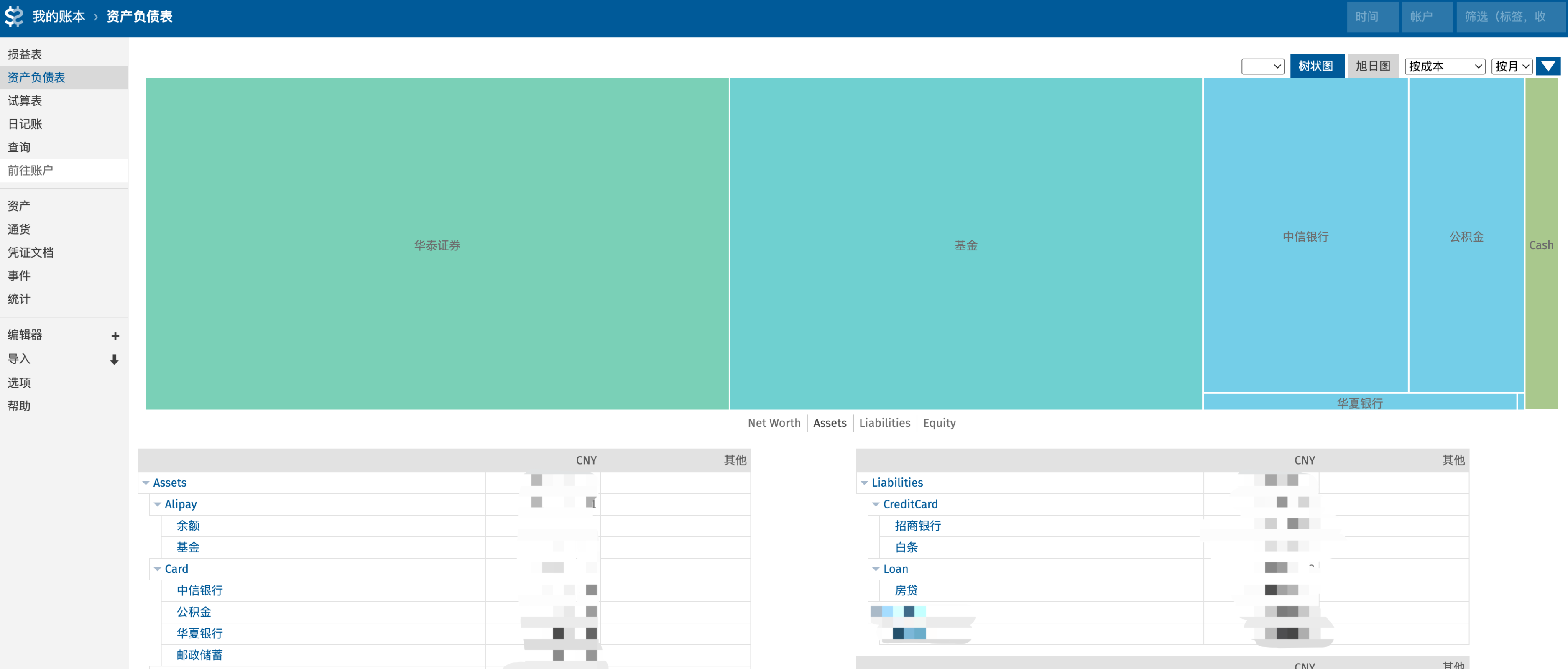
在这里我不会记录怎么安装,配置的细节,而是介绍一些我自己实际搭建的时候遇到的一些坑,以及其他一些教程中没有写的但是又比较关键的点
不用纠结,直接用我已经配好的这个,这是我看了好多教程,整理出来比较合理的项目结构了:
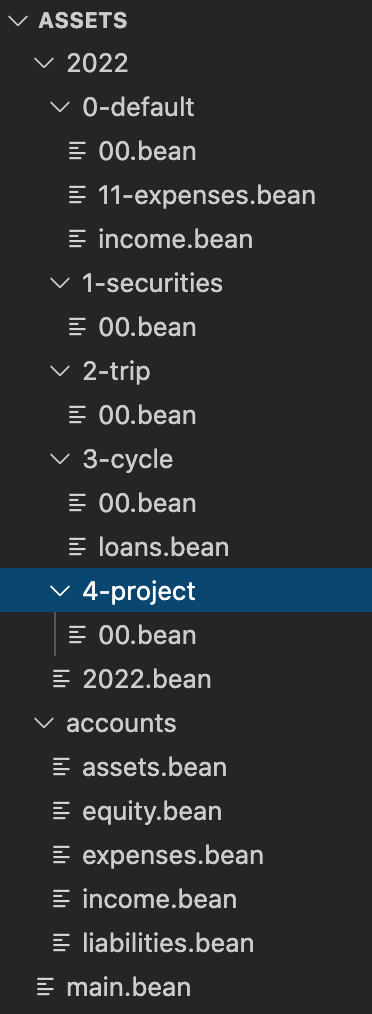
主入口是 main.bean
accounts 下是各个账户的初始化
2022 下是 2022 年的记账流水
第一个坑就是配置 VSCode 插件,beancount 就像编程语言一样,这个插件主要完成了高亮,自动补全。
这些教程里推荐的是这个插件:
但是不是说下载安装就可以用了,安装完成了需要配置,点击插件配置,需要配置一下三个地方:
这样配置完成之后,在 VSCode 里编辑就可以正常高亮和补全了。
因为挖财的数据没法导出来,而且导出来再导入 beancount 也挺麻烦的,还不如重新开始。
重新开始就遇到一个问题,如何新建账户,并且初始化各个账户的初始金额呢?昨天搞了半天,终于弄明白了,有几个关键点昨天一直没弄明白,所以一直有问题:
然后 accounts 文件夹下的这几个文件分别代表以下含义:
下来就是将你的各个资产和负债记录到 assets.bean 和 liabilities.bean,格式其他教程有讲,我就不赘述了,但是有个小坑,就比如下面的这条,中间的 Card 必须是英文,而且首字母需要大写。。。
2022-11-01 open Assets:Card:中信银行 CNY
定义好资产和负债之后,开始在 equity.bean 初始化,大概就是这样:
1 | 2022-11-01 open Equity:OpenBalance ;用于账户初始化,支持任意货币 |
其他账户照这个写就完事了,注意第一列的时间哦,不要写错了。负债的金额写负数就可以啦。
下来是 收入和支出 定义,这个比较随意,按自己的需求来定义即可,比如我的 income.bean:
1 | 2022-11-01 open Income:Salary CNY |
支出 expenses.bean:
1 | 2022-11-01 open Expenses:Shopping:京东 CNY |
这样基本配置就 OK 了,是不是很简单。
在项目结构的 2022 文件夹下的 11-expenses.bean 定义的就是 11 月份的支出,第一笔:
1 | 2022-11-11 * "高速过路费" |
注意,会计恒等式,支出了什么就要从资产中减掉什么,收入了什么就需要在资产里加上什么。那么这里的支出就是用正数记录,收入是用负数记录。
记账的目标不在于记录一个流水账,而应该能帮助我们分析诊断家庭财务的健康度,最终实现家庭的理财规划目标。
在开始记账之后,我们就要逐渐开始思考如何把自己当成一家公司在运营,如何提升自己资产负债表的健康度~
最近工作上遇到了一个比较有意思的问题:在生成邮箱验证码的时候,居然会出现重复,而且是可复现的重复,后来去另一个环境试了下,发现居然不同环境都会重复!
这种情况,粗略判断,应该是随机数生成的问题,但是奇怪的是,代码也重置了 seed,这个 seed 也是个随机的:
1 | import random |
经过调试,发现不论 seed 设置什么值,生成的随机字符串都是一样的,但是如果把 seed 设置放在函数内,就又都是随机的了。
最开始以为是 seed 设置会有作用域区分,但是经过查看代码,发现 random 居然是在内部生成了一个 Random 类的实例,从外部导入的 random.seed,random.sample 都是在这个实例上调用的
1 | # Create one instance, seeded from current time, and export its methods |
那既然不论在全局 seed,还是在函数内 seed,都基于同一个实例,那应该都起作用才对。现在的状态是全局调用 seed 函数,不论传入什么值产生的结果都是一样的。而在函数内调用 seed,如果输入是随机值,那么输出也是随机的,如果输入是个固定的,那么输出也会是固定的随机字符串。
那么这样看来,似乎只有一种可能————有其他地方在这个全局实例上也调用了 seed,于是我把断点打到这个 seed 函数里,然后重启 web,果然发现有很多次调用。
顺藤摸瓜,找到了其他在全局调用 seed 的地方,案子终于破了:其他地方调用 seed 的时机比这个地方迟,而且又都是在一个实例上调用的,那肯定都覆盖了,而且其他地方都是以固定数字调用 seed 的,所以最后产生的随机字符串都是以固定的顺序生成的。
那么如何修改代码呢?
在调试的时候,除了上面的那些全局调用 seed 的地方,还有一些其他写法,那就是新实例一个 Random 实例,让它和 random 模块里内置的那个默认实例区分开,然后后面调用 random 方法的地方,都基于这个新实例。妙啊!
那么 random 库使用的最佳实践应该是 在用到 random 的时候,搞一个自己的 Random 实例,这样就分开了。
代码修改如下:
1 | import random |
学会新技能总是令人振奋,最近学会了如何给网线压水晶头以及如何将网线接到网线插座上。
首先一根网线里面有8根线,分别有不同颜色的外皮,如下图
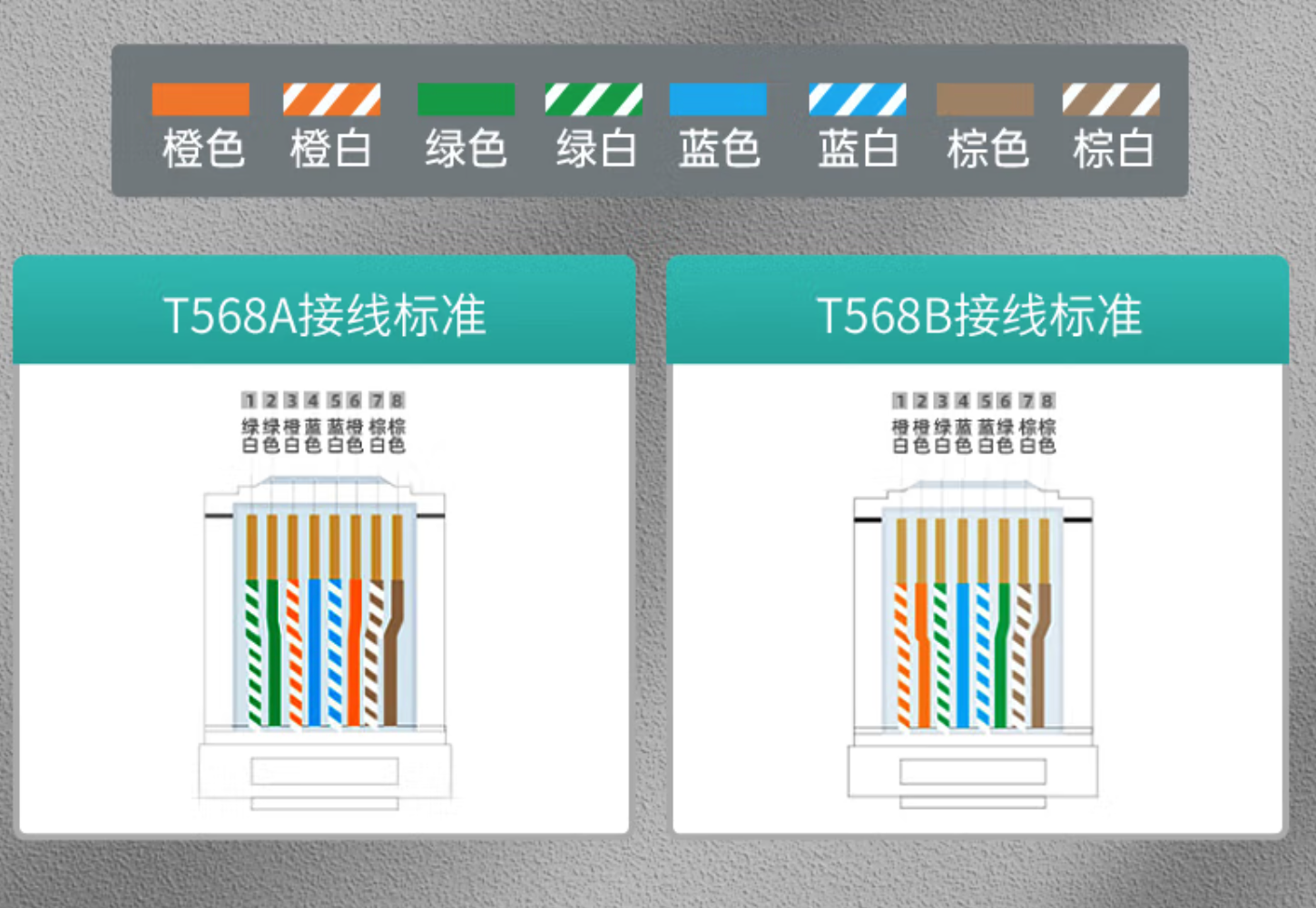
一般来说有两种接线方法,即上图中的T568A和T568B。以前还需要区分这两种线序,其中网线两头都是T568B被称为直通线,用于不同设备的连接,比如电脑和路由器;网线两头一边是T568A接法,一边是T568B接法,这种被称为交叉线接法,常用于相同设备的连接,比如电脑连接电脑。
是不是觉得头大,哪个该接哪个呢,所幸的是现在的设备都已经具备了自动逆转的功能,所以我们只需要全部接一种接法就好了——通通按T568B接法进行连接。
我家的户型图以及网络规划如下图:
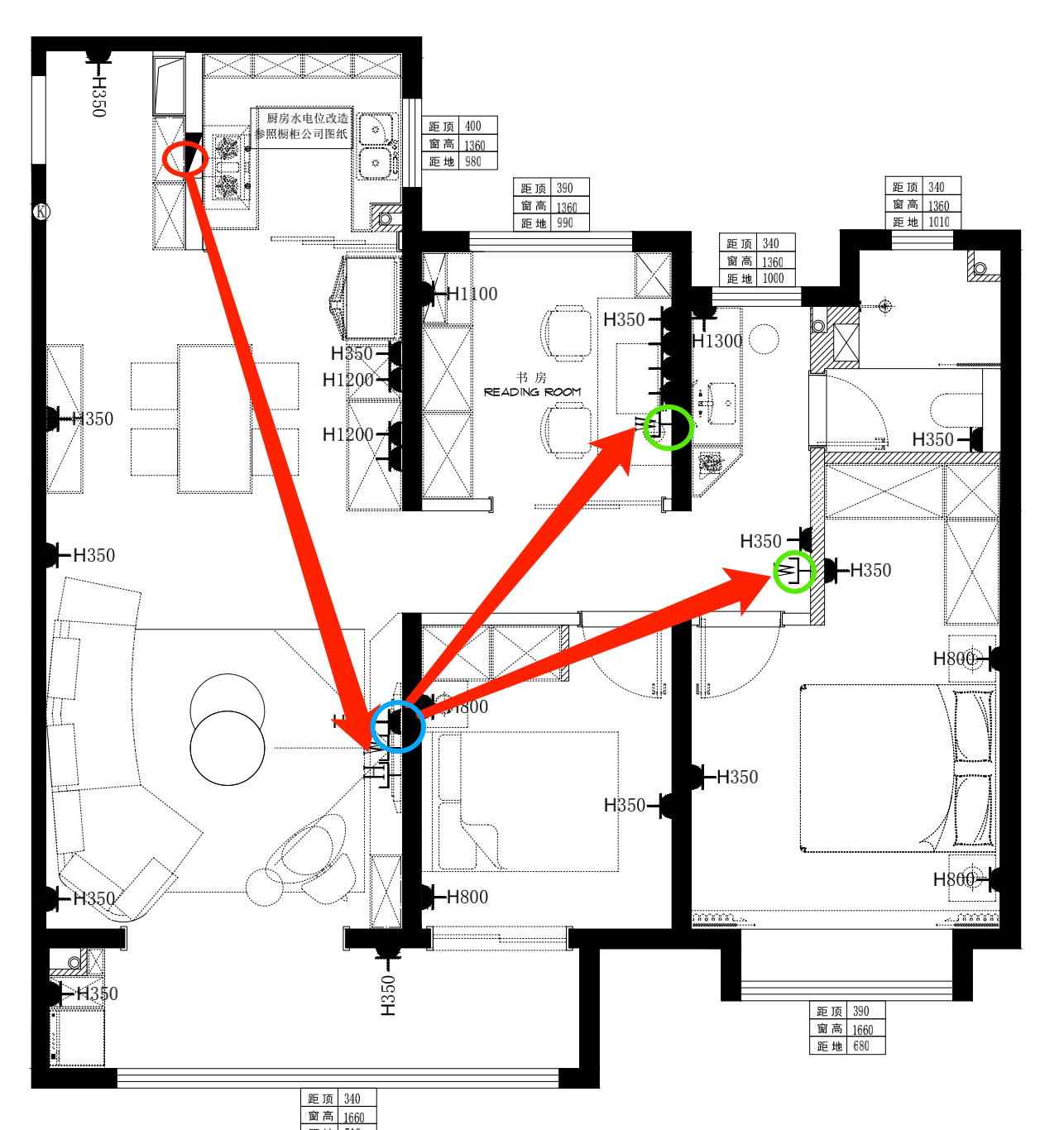
红圈的地方是弱电箱,光猫在这里,然后蓝圈的地方是主路由器,绿圈的地方是网络插座。然后光猫往主路由器有一根网线,主路由器往两个网络插座各有一根网线。
在过道最里面这个网络插座附近将来如果需要会配置一个路由器,和主路由器形成一个mesh,以弥补主卧和卫生间区域网络信号的不足。
现在我需要做的工作就是:
之所以先介绍如何接网线插座,因为网线插座接起来最简单,哈哈。
无论是网络插座已经装到墙上了还是没有,反正想办法把接线端子搞出来,接线端子上有A,B两种标识,然后对应有接线的颜色,我们就按B来接,如图:

接线就是将对应颜色的线压到每个对应端子里,然后用压线刀把线卡到里面,很简单,记得一定要卡严实了,当然也不要太大劲把端子整坏了。
线压好之后,先不要着急往墙上装,因为还有一步:检测线是否接好。
但是要进行检测,那么客厅区域的网线就需要将水晶头压好。
重头戏来了,水晶头一开始因为知识掌握不牢固,操作不熟练,直接废了3根水晶头,中途陆续又接废了几个,到最后4根网线竟然用了10个水晶头才接好🤣
好了,废话不多说,开始正题
接水晶头第一步是要确认网线规格,可以粗略分为两类,六类之前和六类之后,为啥分为这两类,因为这两类使用的工具不一样,所以一定要先分清楚网线规格。其中六类之后目前就只有超六类和七类。
网线规格在网线外的包皮上可以找到,我家的是CAT6A,也就是超六类网线,超六类网线和七类网线工具是共用的,那么我就在京东上买了七类网线的压制工具。
上二维码,这是一个视频教程:

我就总结下要点:
先按照橙白,橙色,绿白,蓝色,蓝白,绿色,棕白,棕色整理好线束,然后开始分层处理:橙白,绿白,蓝白,棕白放到下层,从下层穿过束线卡,然后橙色,蓝色,绿色,棕色,从上层穿过束线卡,留好足够的距离,将束线卡另一侧多余的线束剪掉。
这里非常重要,我就是没注意这块,弄反了,白给了好几个水晶头。
方向是:花色线束所在的位置靠近水晶头有塑料弹簧片的一侧,纯色线束所在位置靠近水晶头有金属针脚的一侧
这里还需要注意,因为超六类和七类网线都比较粗,所以需要先把后面网线压扁,这样好怼进去。
怼进去,怼到头,这时候从水晶头往里面看,可以清晰看到各线束的金属触点,这样才算OK。
用网线钳可以压燕尾夹,但是注意力道,不要把网线压坏了。我就是虽然水晶头接好了,但是用力过猛把网线压坏了,又一次白给。。
好了,到这里水晶头已经接好了,下来就是测试部分。
工具箱里有网络测试仪,因为我需要测试的网线两端距离比较远,所以需要将网络测试仪分开。
然后分别插上网线,打开网络测试仪开关即可。
这里不论你看哪边的测试仪都可以,因为联通是亮灯,不通就不亮,所以只需要看一边即可。

好了,到这里就全部结束了。
为啥我要自己接,因为我们工长说电工不会接,请外面人接需要300块,那我一想还不如我在京东上买套工具200块,自己接,还能学会一个新技能,何乐而不为?哈哈。
以前也写过一些前端,比如我自己的博客,就是用 JQuery+HTML+CSS 实现的,但是大部分都是抄的,特别是 CSS 样式,真让人头大。至于 JS 部分,也是现学现撸,很不成体系,更不用说更深入的语言细节了,那就是一塌糊涂。
最近浏览博客,发现之前关注的博主 miguelgrinberg.com 开始在写 React 的教程,所以打算跟进学习一下,正好了解一下现代的 JS 框架是怎么样的,学习下前端工程是怎么构建的。
听说成为全栈工程师能更容易拿到远程工作的 offer,嗯不错不错,开始搞吧,学习使我快乐~
教程地址:Introducing the React Mega-Tutorial
我会在博客里记录一下有意思和对我来说重要的点,主要就是个笔记吧。
ECMA, ECMAScript
transpiling:which converts modern JavaScript source code into functionally equivalent ES5 code that runs everywhere.
很有帮助的观点:
1 | const myArray = [ |
在最后面一个元素加上逗号有两点好处,一个是上下挪动比较方便,另一个是新加元素比较方便。
这里其实没有完全理解,default export到底和其他export有什么意思,文中说了一句话:When using default exports, the name of the exported symbol does not really matter.
后面举的例子,说 import myReallyCoolFunction from './cool'; 也是有效的,那和 import myCoolFunction from './cool'; 是一个意思?
也就是说 default export 的东西,因为一个模块只能有一个,所以在其他模块引用的时候可以随便用任何名字?
先保留这个疑惑,继续往下看。
另外导入 non-default export 也有一点不一样,需要加大括号 import { SQRT2 } from './cool';
使用 let 来声明变量,const 来声明常量。
1 | let a = 1; |
常量就是赋值之后不能有新的赋值了,而且也必须是在声明的时候赋值。
=== 和 !==
1 | const name = 'susan'; |
1 | const allTheNames = ['susan', 'john', 'alice']; |
之前 code review 的时候看过这种写法,觉得很神秘,现在详细了解之后,其实也没啥,正如 Python 里的匿名函数,lambda 表达式一样。
1 | function mult(x, y) { |
在 Python 里就会这么写
1 | lambda x, y: x * y |
1 | fetch('http://example.com/data.json') |
上面的写法可以改成这样,更易读
1 | async function f() { |
加上 async 的函数会自动返回一个 promise
箭头函数也可以使用 async
1 | const g = async () => { |
工作中需要写一个 SQL 进行查询,本来我是这样写的:
1 | SELECT document.id, (COALESCE(CAST(document.internal_info->>'proofread_time' AS int), 0) - p500_end.end_utc) / 60 AS proofread_time |
但是发现报这样的错误:
ERROR: column "proofread_time" does not exist
然后我把 WHERE 条件里的 proofread_time 替换成 (COALESCE(CAST(document.internal_info->>'proofread_time' AS int), 0) - p500_end.end_utc) / 60,就正常了。
咦,好奇怪,难道 alias 不能在 WHERE 条件里用吗,有点反直觉,于是我去查了下文档:
An output column’s name can be used to refer to the column’s value in ORDER BY and GROUP BY clauses, but not in the WHERE or HAVING clauses; there you must write out the expression instead.
原因就是 WHERE 语句和 HAVING 语句是在 column aliases 之前做的,所以没法引用,而 ORDER BY 和 GROUP BY 是在其之后,所以可以使用 aliased column
很古怪吧,反直觉!
但是把这么一长串的表达式写两遍真的很难受,所以我使用了 WITH 表达式来解决这个问题:
1 | WITH results AS ( |
这样看起来就清晰多了。