明天大阳线
有两个标的已经拿了9个交易日了,但是一直亏,真的今天我都想把他俩卖了,好来个解脱,但是交易系统说不卖,好吧,我忍住了。
我还是选择相信交易系统!
现在情绪已经到最极端的时候了,所以我觉得明天大概率大阳线反转!
不论这次结果如何,我都认了。
就这样。
——————————————
2022.10.26更新
已经全部割肉卖出,失败了。辣鸡!
有两个标的已经拿了9个交易日了,但是一直亏,真的今天我都想把他俩卖了,好来个解脱,但是交易系统说不卖,好吧,我忍住了。
我还是选择相信交易系统!
现在情绪已经到最极端的时候了,所以我觉得明天大概率大阳线反转!
不论这次结果如何,我都认了。
就这样。
——————————————
2022.10.26更新
已经全部割肉卖出,失败了。辣鸡!
自从上周五被封控以来,宅在家的生活就是:做饭,吃饭,上班,做饭,吃饭,睡觉。

什么时候疫情才能消失啊,炒鸡想出去玩,自驾新疆,西藏。。。
交易系统全标的收益率回测新高了,目前总收益率27.47%,平均每个月2.6%!
但是因为我是从2月份开始跟踪的,而且第三季度去玩了会股票,试了试其他策略,导致第三季度收益率-10%,而交易系统第三季度收益率是2%,这一下就差了12%。
哎,不能瞎搞了,管住手,按既定规则交易。
有人说,即使给你一个90%可能能盈利的交易系统,你也不一定能盈利,我深刻的体会到这句话是啥意思了。有人会觉得很简单,但是你实盘操作一下就知道有多困难了:
另外交易系统也需要经历实战检验。没经过实战检验的交易系统,只是理论上的,必须理论联系实际,才知道交易系统的效果。才清楚什么地方需要改进,什么地方需要完善等。只有经过实战的交易系统,才知道是否能持续稳定地获利。
加油吧!稳定复利,最小回撤,做时间的朋友。
不仅仅是之前的早醒以及早醒后睡不着,最近这两天连续两天做噩梦,第一天的梦是回老家了,真的无论是现实还是梦中回老家,我都是精神紧张,非常疲惫。
而昨天晚上的梦更加严重,直接开始鬼压床了。
昨晚上大概10点钟开始睡觉,睡着我估计10点半,到1点15的时候第一次醒来,去上了个厕所,排量比平时多一倍,也许是水喝多了,哦对晚餐喝了一大碗小米南瓜粥,然后好像还喝了一杯水。
然后回来继续睡觉,这一次就开始做噩梦了,还是一个嵌套梦,梦中梦,梦见我躺在床上做梦,梦见我躺在床上,然后有各种类人类鬼的东西在客厅,然后我就起来去打架,后来发现是一场梦,然后嵌套的第一层的我,也发现了客厅有类人类鬼的东西,然后出去干架,发现是自己跟自己打架,然后现实的我特别想起来,睁开眼睛看一看,客厅到底有没有东西,有没有危险向我靠近,但是睁不开眼睛,也动不了,在挣扎了很久之后,终于逃脱出来,睁开了眼睛,这时候3点钟左右。
下来就不像之前那么容易睡着了,我估计挨了三四十分钟,睡着了,当然也是浅睡眠,这个时段的梦大概就是老家的事情,让我焦心,这个梦现在没啥印象了,主要还是前一个梦太吓人,太费脑子,太令人印象深刻了,这次睡着醒来大概是6点40分。
真的,这一觉睡的我真的很累,这两天的觉睡的我都很累,真的有点扛不住了,现在都能感受到心跳声,整个身体都很沉重。
不行了,真的该去医院了,好怀念能一觉睡到天亮的时候。
唉。
昨天晚上突发灵感,给策略加上了一条非常简单的优化,发现对于某些标的提升十分明显:
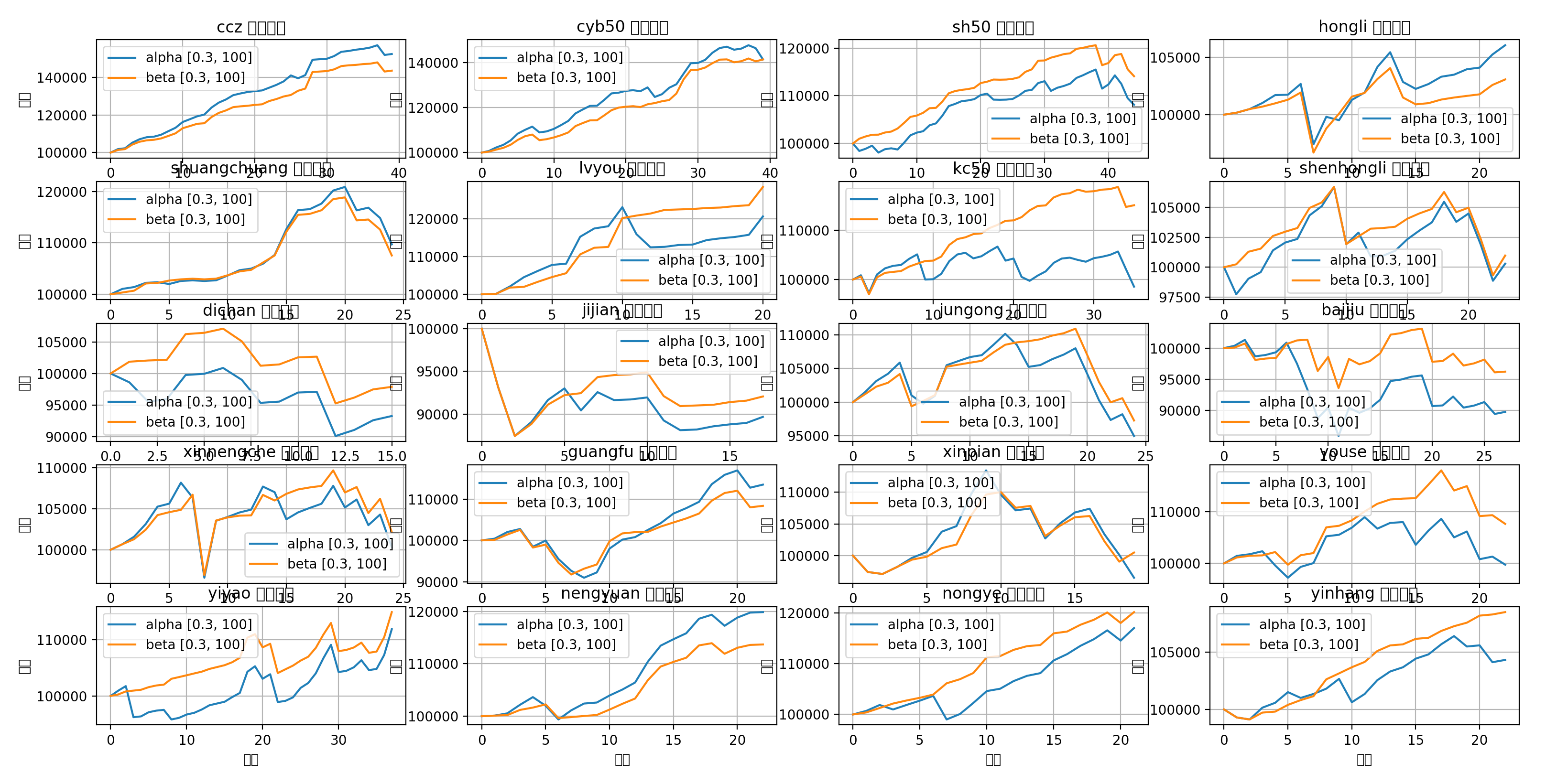
图中蓝线代表之前策略回测结果,红线代表最新的回测结果
可以看出在某些标的上提升非常明显,其他标的或者是略有提升,或者是略有下降,但是总体上这条优化属于可以纳入的范围。
其实非常简单,就是一个点:只要挣钱了,能卖就卖。
在各标的组合回测中:
仅做主线组合里,收益率似乎差异不大,但是就最近一次来说避免了大幅度的回撤
全标的组合两者最终收益率也是差不多,但是优化后曲线更平滑,收益更稳定,回撤更小
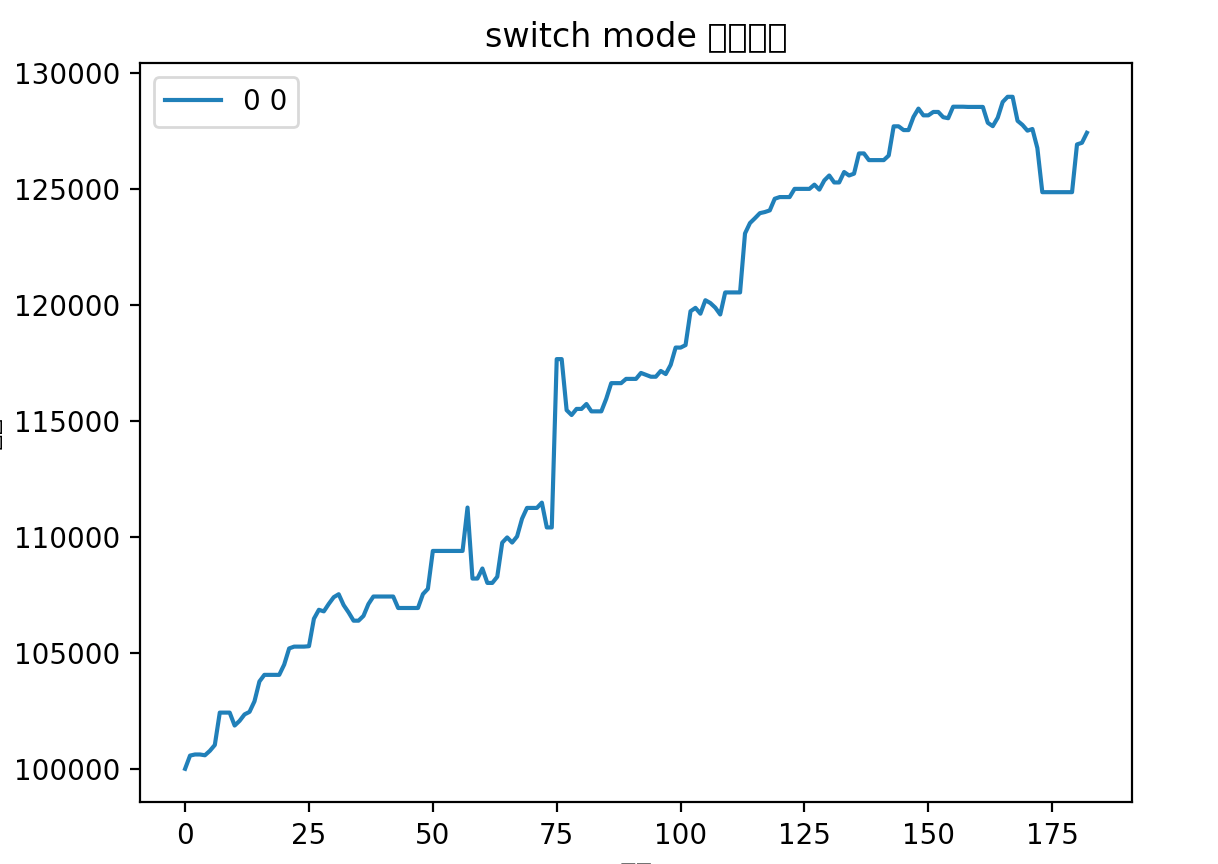
对比以前的曲线:
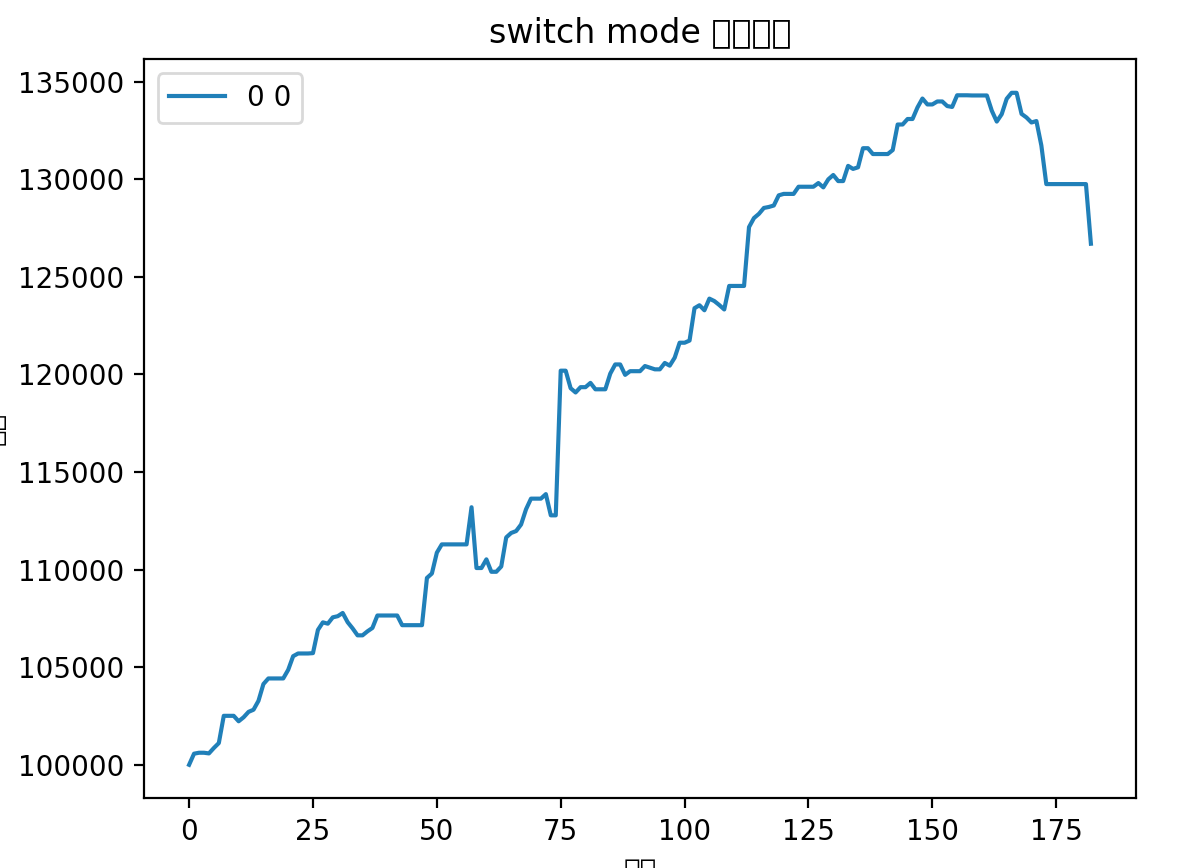
从更长时间(18个月)跨度来看,收益率也是差不多的,主要差异还是在避免了最后一次回撤
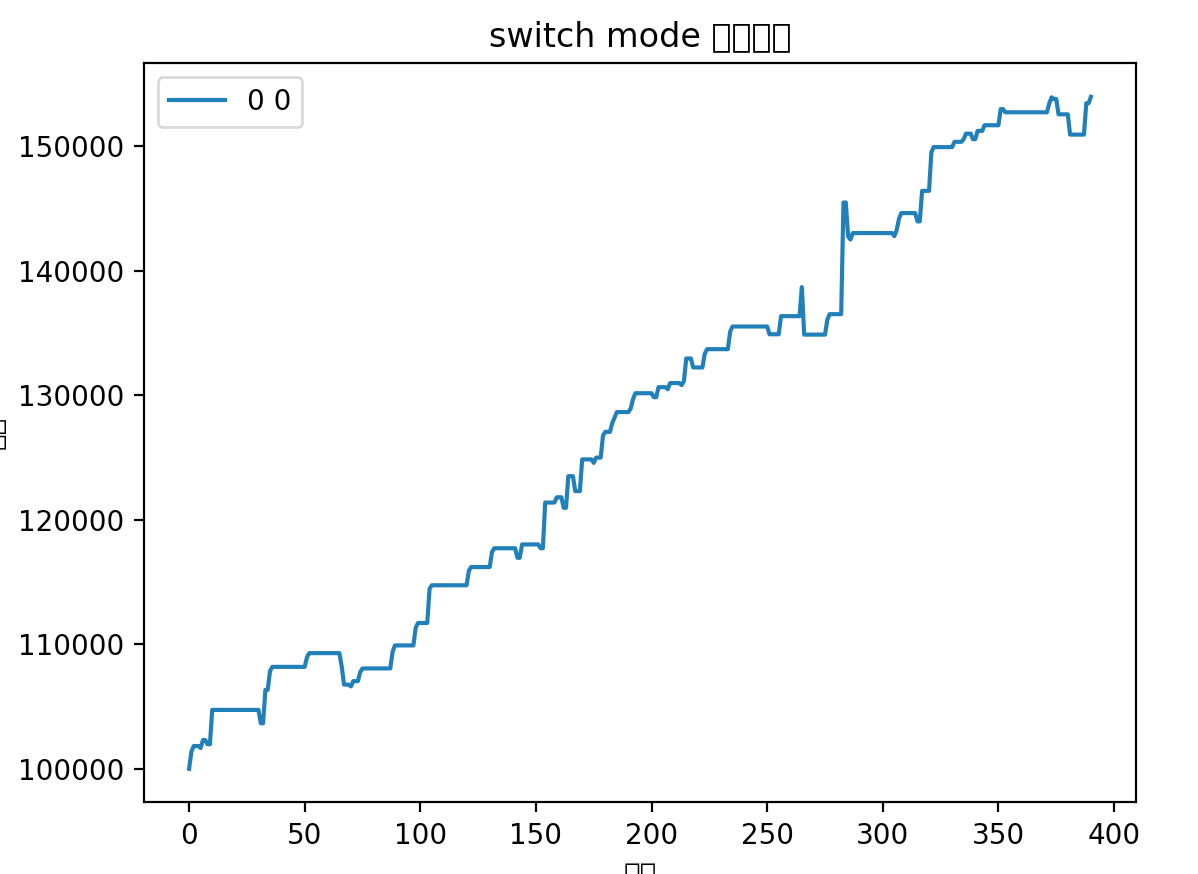
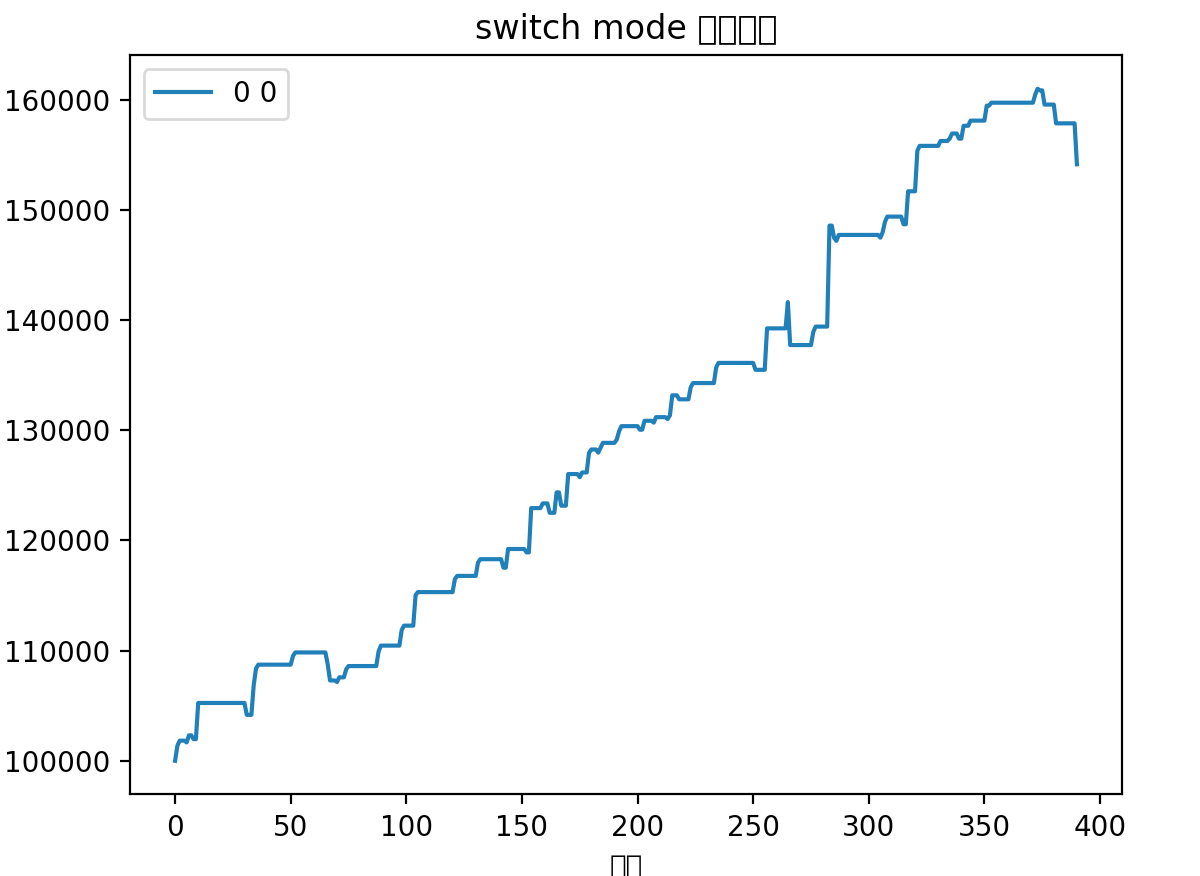
总的来说,新的优化可以平滑波动,减少回撤。主要差异在于之前策略会博一个高开,这个高开经常会有比较大的幅度,体现在收益率曲线上就是突然的大幅提升。但是如果博失败的话,就容易有大幅度的回撤。所以在行情好的时候用以前策略会拿到更好的收益,在行情不行的情况下使用这个优化能取得更稳定的收益。
那么行情好坏有一个最容易判断的方法:买入就赚还是买入就亏,买入就赚,说明行情好,可以去博弈一下,买入就亏说明行情不行,保本出。
然后提升明显的标的,那就直接应用新优化,提升不明显的标的可以应用变通的策略,行情好去博弈,行情不好保本出。
按这一思路修改之后,果然有所提升,看来以后需要灵活判断了
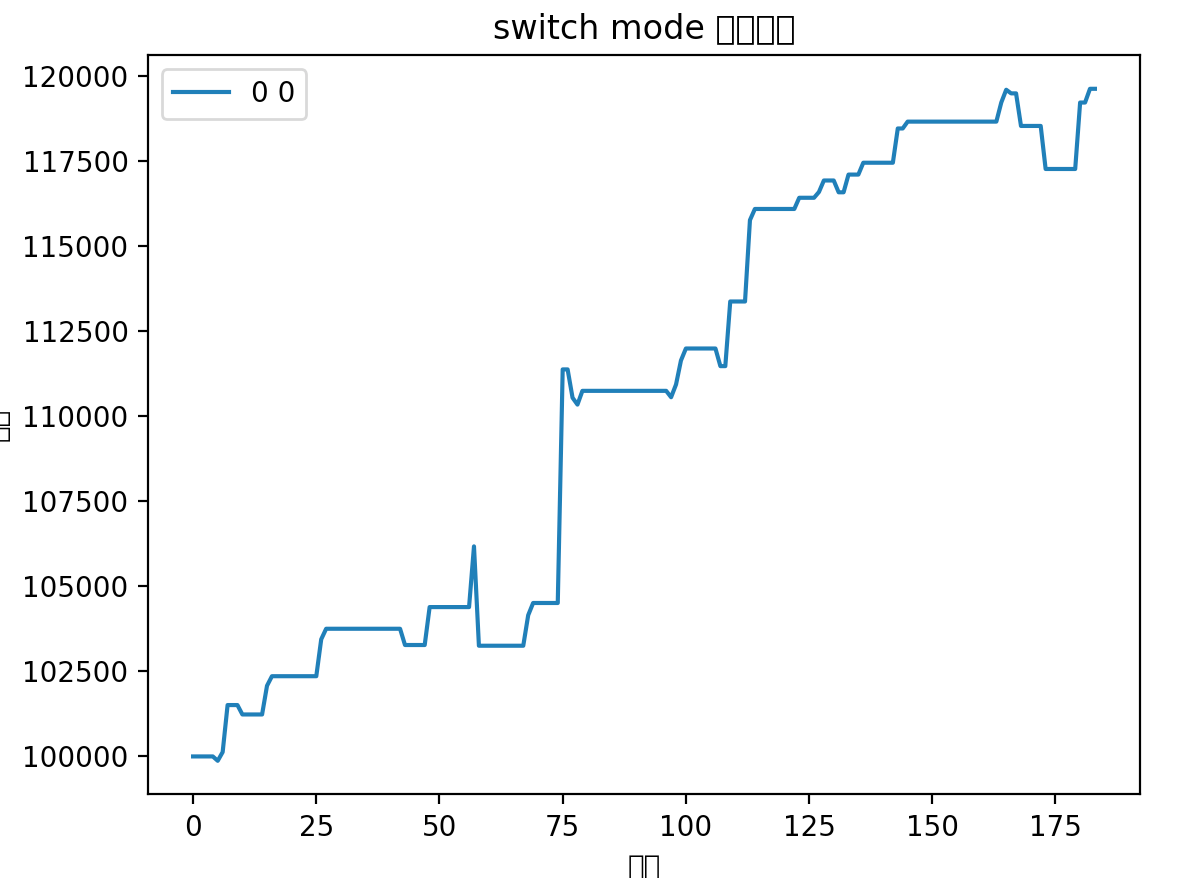
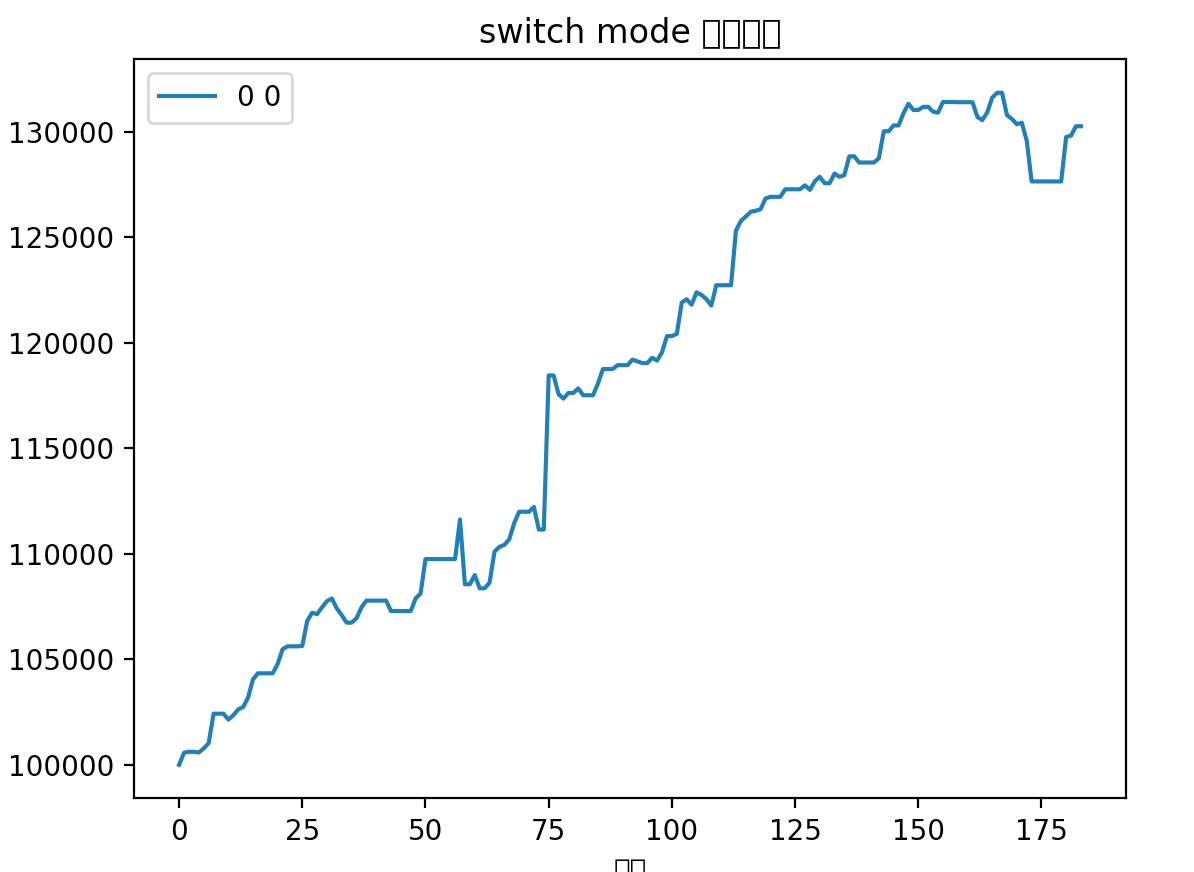
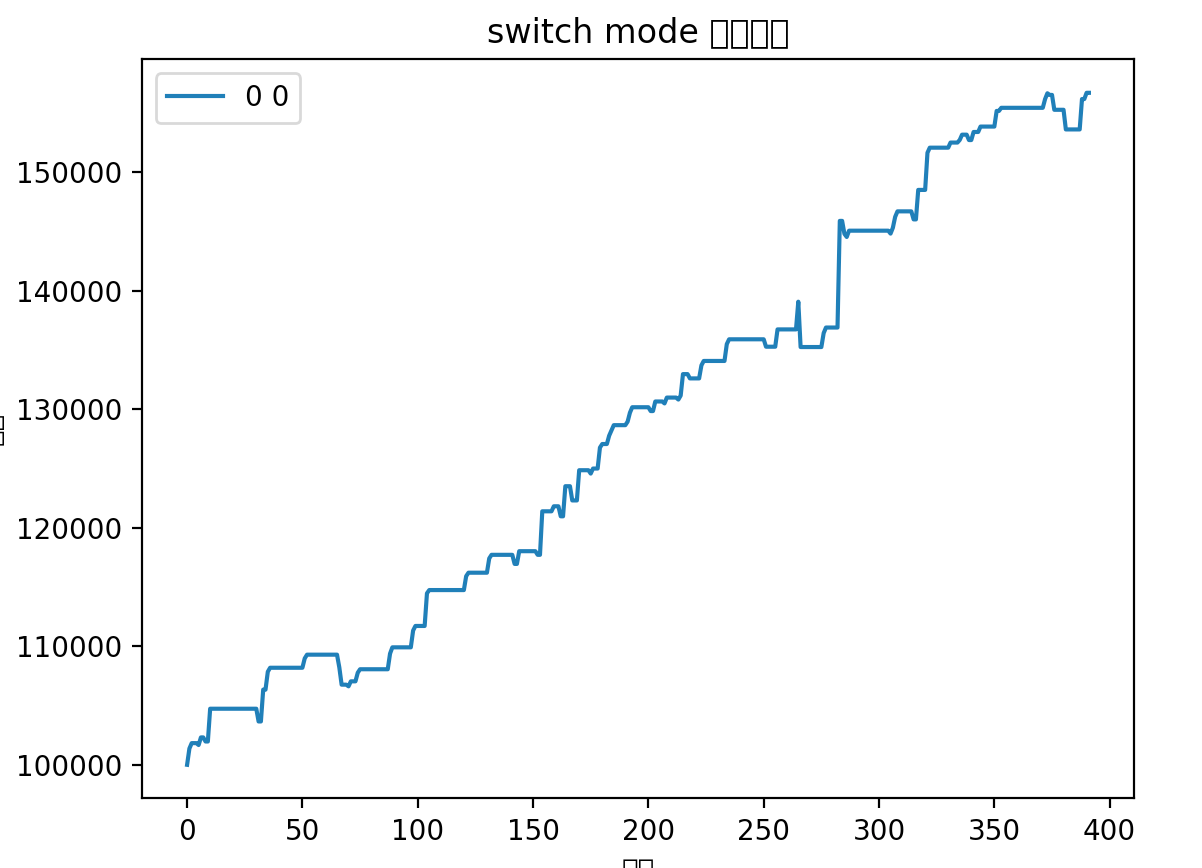
整体而言应用新优化可以更好的做到稳定盈利,最小回撤。在目前这个初始积累阶段,还是更需要资金的稳定增长。
今年国庆下了一周雨,也没有出去逛
宅家做饭给宝宝们(媳妇和娃🤗)补充营养

10.5日去医院做建档和产检,抽了媳妇十一管血,完了之后还得做尿检等其他检查,真是太辛苦了,我看着都心疼。
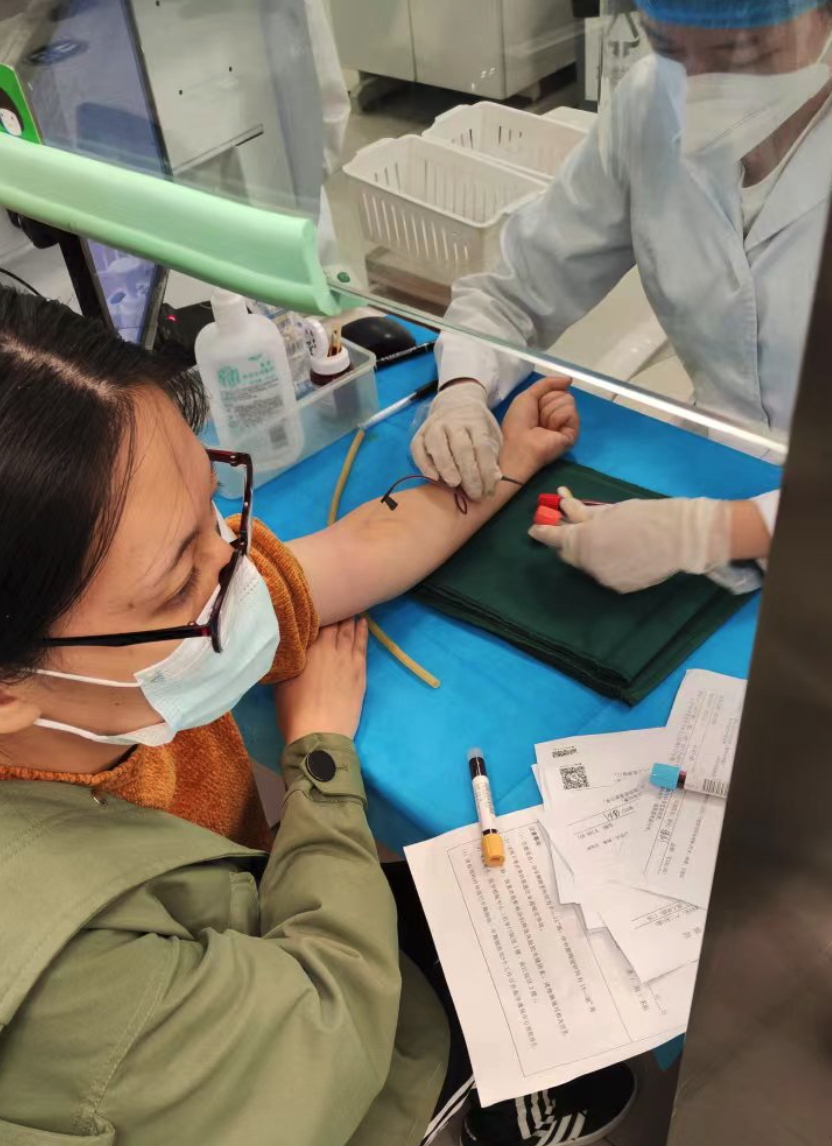
国庆虽然没能像以往出去来个长途旅行,但是宅家的日子也过的美妙而幸福。
期待宝宝出生的那一天,还有193天。
Casdoor 的权限检查机制是基于 Casbin 的,参考文档:
所有在同一个组织的用户可以访问该组织下的所有应用,但是有时候需要做一些限制,这里就要用到 权限(permission) 了。
那么 权限(permission) 的作用就是用于控制 用户 能否对 应用 进行某些 操作
最简单的方式就是在 权限(permission) 配置页面新建一个权限,如下图所示:
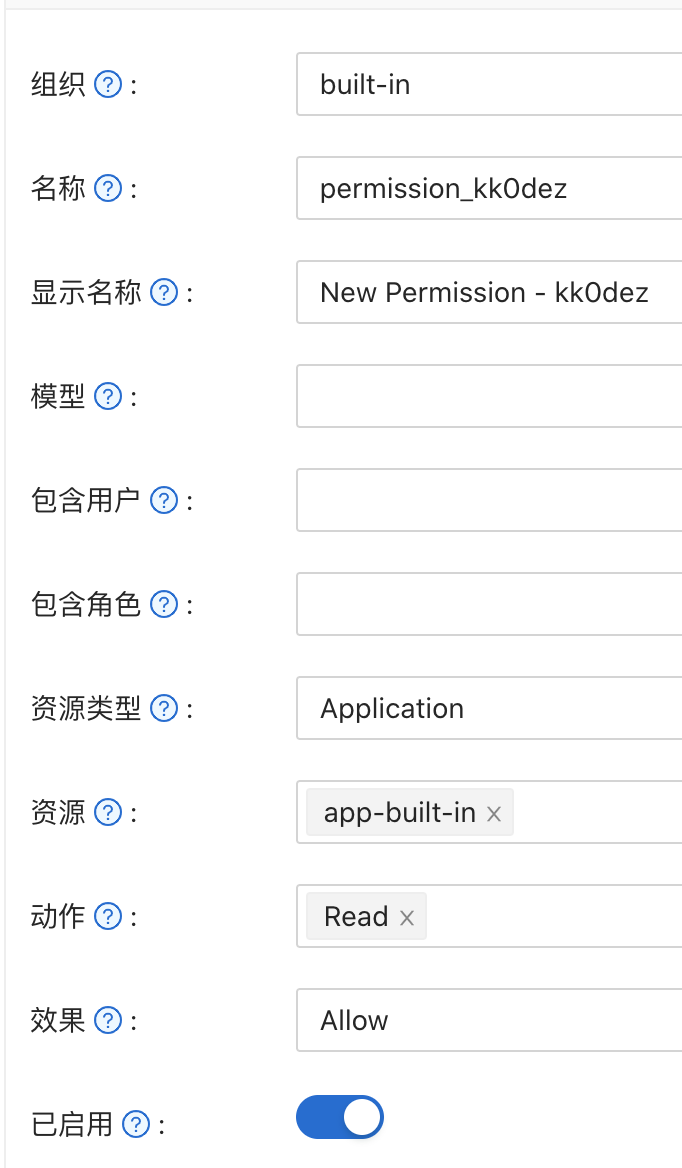
作为三个要素,用户,应用和操作,在这里是需要配置的:
意义也比较简单,就是哪些 用户 可以对哪些 应用 进行哪些 操作
包含角色 也容易理解,一个角色对应多个人,所以这里就是用来控制一组人的。
那上面的模型是什么意思呢,Casdoor 是如何根据这个配置进行权限校验的呢?
ACL 权限控制模型应该很熟悉了吧,Linux 上就在使用,这里就不再赘述,参考:
Casbin 是一个开源的权限控制库,它支持了多种权限控制模型
Casbin 实施权限规则比较简单,管理员需要列出 主体(subject),对象(object) 和期望允许的 操作(action) 即可:
管理员需要定义 模型(model) 文件来确定校验条件,Casbin 提供了一个 执行器(Enforcer) 来根据规则定义和模型文件来校验请求。
也就是说 Casbin 权限校验需要三个部分:模型(Model), 校验规则(Policy)和执行器(Enforcer)。
执行器是 Casbin 自带的,可以不必特别关注,只需要知道这件事情就行。下来着重研究模型和校验规则。
哦,对了进行权限校验还需要一个 请求(request)
Casbin 里的权限控制模型被抽象成了一个 CONF 文件,基于 PERM metamodel (Policy, Effect, Request, Matchers),这个 PERM metamodel 基于 4 个部分 Policy, Effect, Request, Matchers,其描述了 资源 和 用户 之间的关系。
Casbin 里最简单的一个模型,也是默认模型:
1 | [request_definition] |
r = sub, obj, act
定义了请求参数,也就是说请求需要三个部分,subject,object 和 action,通俗点讲就是 访问的用户,访问的对象,访问的方法。
这里其实定义了我们应该提供给权限控制匹配函数的参数名和顺序。
p = permission, sub, obj, act
定义了模型的访问策略,其实是定义了在策略规则文档中字段名和顺序
这里还有一种定义:p={sub, obj, act, eft}
eft是可以被省略的,eft代表的是策略的结果,比如就是 allow 或者是 deny,如果没有定义的话,读取策略文件的时候就会被忽略,默认会返回 allow
m = r.sub == p.sub && r.obj == p.obj && r.act == p.act
请求和策略的匹配规则,这里 r 就是请求(request),p 就是策略(policy)
e = some(where (p.eft == allow))
就是对策略的结果再次进行条件判断,这里的意思就是只要有一条规则返回的是 allow,那么整个就是 allow
还有这样的定义:e = some(where (p.eft == allow)) && !some(where (p.eft == deny))
就是说有一条是 allow 而且 没有 deny 的情况,整个结果是 allow
这里主要是针对多条匹配规则都匹配上的情况做处理的
我们已经了解了模型的定义规则,那么就开始在 Casdoor 上面实际操作一番吧。
模型定义用来针对要控制的 object,访问的 subject 能允许怎样的 action
首先在页面顶部导航栏点击 模型(Model),点击新增:
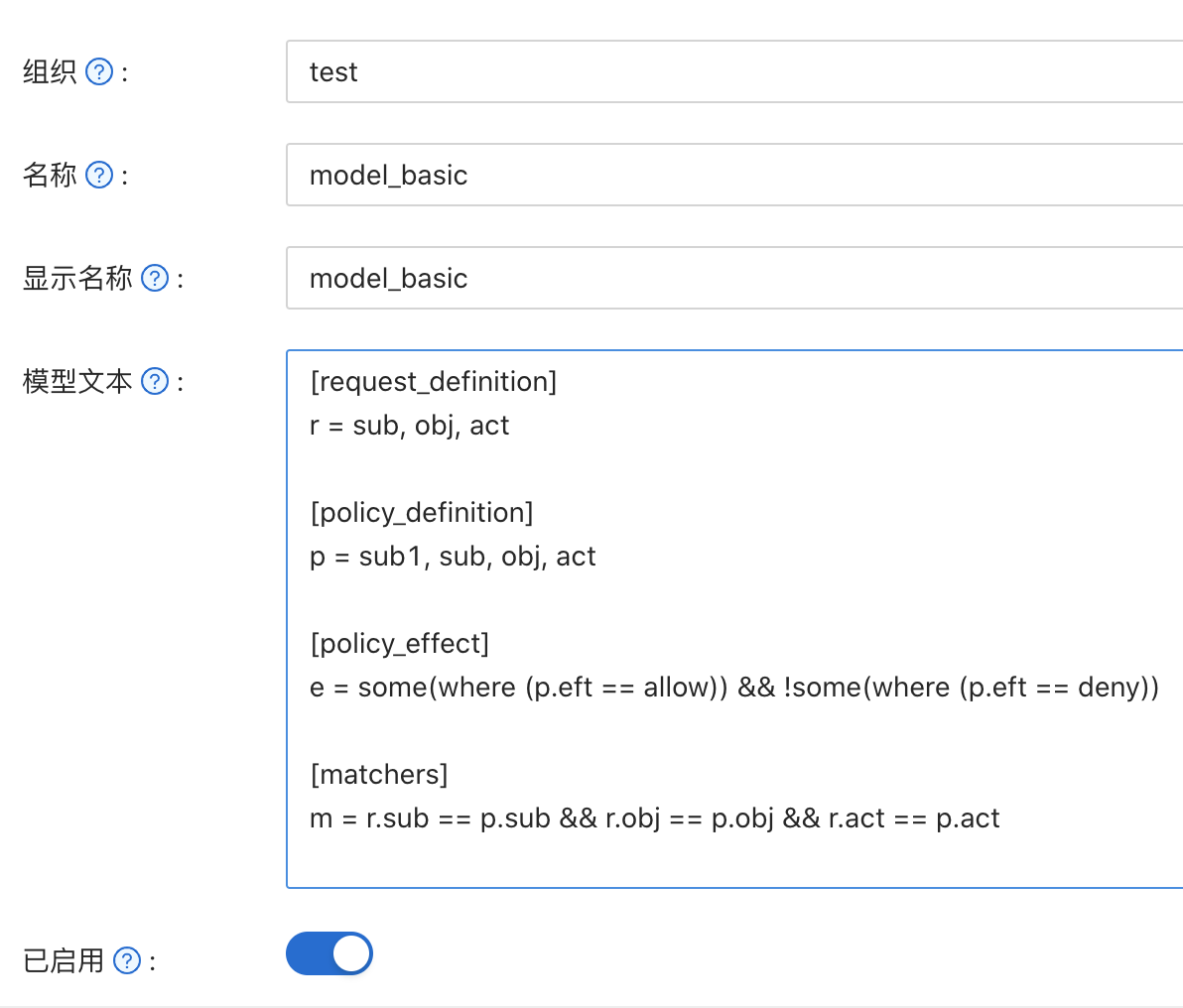
模型文本这里就填写上面介绍过的模型定义字符串,点击保存&退出。
在页面顶部导航栏点击 权限(permission),点击新增:

permission 其实就是具体的控制权限设置,可以针对多个资源进行控制
其实这里的配置界面只是简化了规则的配置,这个页面的权限其实会转换成类似如下的数据:
1 | p alice data1 read |
代码上

permission 里定义的规则会先转换成 CasbinRule 对象,每一个对象就包含了 Policy 定义的每个字段,之后就会转成如下的字符串:
p, built-in/permission-built-in, built-in/app-built-in/admin, app-built-in, read
模型和权限定义好之后,对应被控制的用户访问被控制的应用时,Casdoor 就会进行加载对应模型和权限进行校验,执行这一工作的叫做 Enforcer
关于 Enforcer 的文档:New a Casbin enforcer
流程已经分析差不多了,让我们看看代码上是怎么处理的
Casdoor 是在这个函数做权限校验的。用户登陆时候就会调用,当然在任何你想进行权限校验的地方,都可以进行调用。
1 | func CheckAccessPermission(userId string, application *Application) (bool, error) { |
逻辑就是通过 organization 来获取所有的 permission 配置,接下来遍历 permission 中定义的 resource,如果跟当前的应用匹配,那么用这条权限去检查用户是否有对应的权限。
匹配成功之后,调用 getEnforcer 来获取一个执行权限校验的 enforcer。
1 | func getEnforcer(permission *Permission) *casbin.Enforcer { |
getEnforcer 做的工作就是根据 权限(permission) 数据去看有没有定义好的model,有的话使用定义好的模型文本来加载 enforcer,否则使用默认的模型文本:
1 | [request_definition] |
加载模型文本之后,enforcer 就会加载对应 权限(permission) 所对应定义的规则,对应 LoadFilteredPolicy 函数。
这些数据加载完成之后,enforcer 会根据传入的 subject,entity,action,即 用户,应用,操作,来检查权限是否允许
allowed, err = enforcer.Enforce(userId, application.Name, "read")
总结一下,主要有以下核心:
在代码上新建或者编辑权限(permission) 之后,记得要重新生成一下规则(policy),因为不论在界面上是怎样的表现形式,最后都是enforcer通过model text和policy来检查request的
代码如下:
1 | // 更新permission之后需要调用 |
生活逐渐回归正轨,一切都开始尘埃落定。这两个月事情实在是太多,而且很多事情不受自己控制,我又是那种想的很多,容易焦虑的人,所以搞的很疲惫。现在终于清净下来了。
除了这两件长时间困扰人的事情,中间还穿插了车在车库被撞,修了2个星期。。
现在慢慢觉得越长大,要处理的事情,要担的事情就越多,为什么不想长大,不就是因为小孩子无忧无虑,不需要扛这些事情,有父母大人护着你。
说起父母,家庭,我还是不知道怎么解决,从今年3月到现在,我没回过老家,也没有跟父母联系过,感觉像是3月份之后,大家不约而同的有一点不好意思联系对方一样,另外我也不知道怎么面对,我想起来就头脑如麻,真的是没有办法。
算了,还是先不想这些事情了,因为想也没有办法解决,还是先把眼前的事情解决好吧。
运行go run main.go,时候报 get 包 timeout,应该是代理问题,解决办法就是:go env -w GOPROXY=https://goproxy.cn,direct
如下:
1 | duguangting@c123:~/casdoor$ go get github.com/RobotsAndPencils/go-saml@v0.0.0-20170520135329-fb13cb52a46b |
后端跑通之后,前端运行yarn install的时候报:
The engine "node" is incompatible with this module
解决办法:
yarn install --ignore-engines
在Goland里所有引入的外部包无法跳转,搜了一下,大概这样:
在 Goland 的 go modules 设置勾选,然后设置 GOPROXY
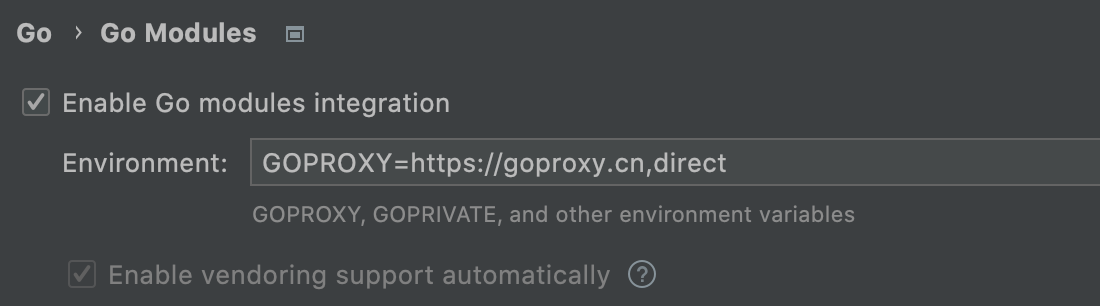
然后因为项目已经有 go.mod 文件了,那么直接执行 go mod tidy,这个命令的作用就是:add missing and remove unused modules
然后就 OK 了
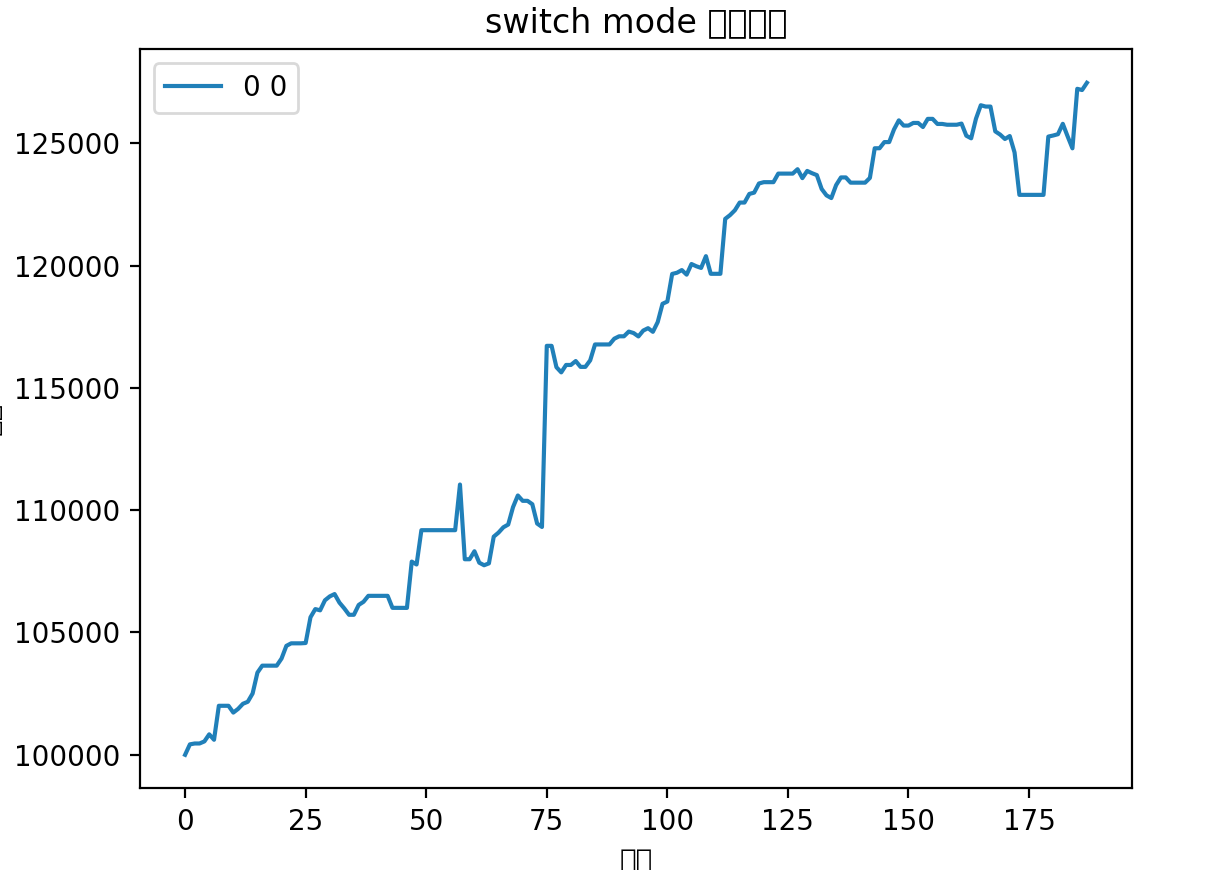
最近FIRE基金刷新了从2022年2月以来的最大回撤,目前为止为6.18%。
究其原因,并不是操作的问题,而是系统性原因,8月和9月市场行情不太行,导致每次上车都是白给,而中秋节后更是如此,在节后第一天上证50,深红利,银行等诸多标的提示买入信号,最后竟然买入到了满仓,其实那时候觉得应该也会继续上涨,没想到后面连续4天回撤了快3%!
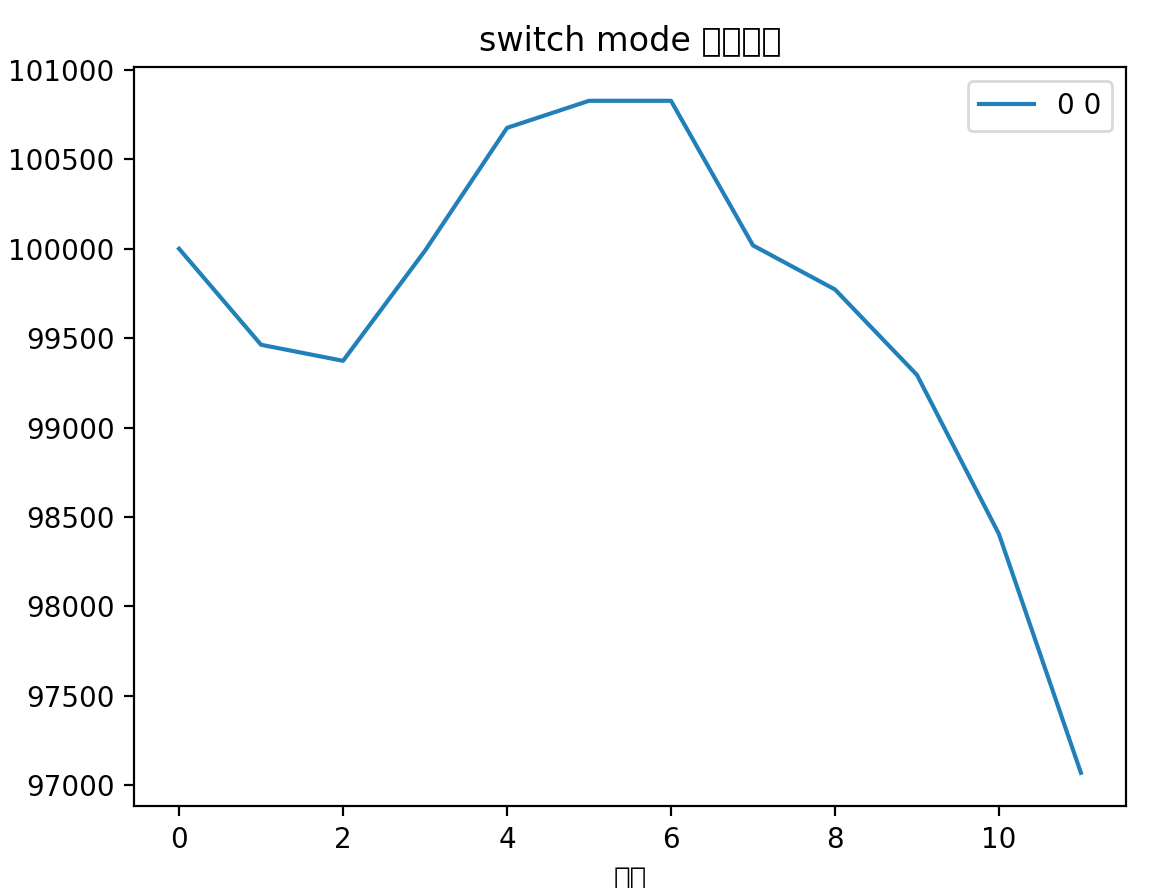
从9月份系统回测图可以看出来,确实有巨大的回撤。
但是我的目标是最小回撤,稳定复利,高达6%的回撤可是不能接受的,而且这个回撤还不一定会结束 orz…
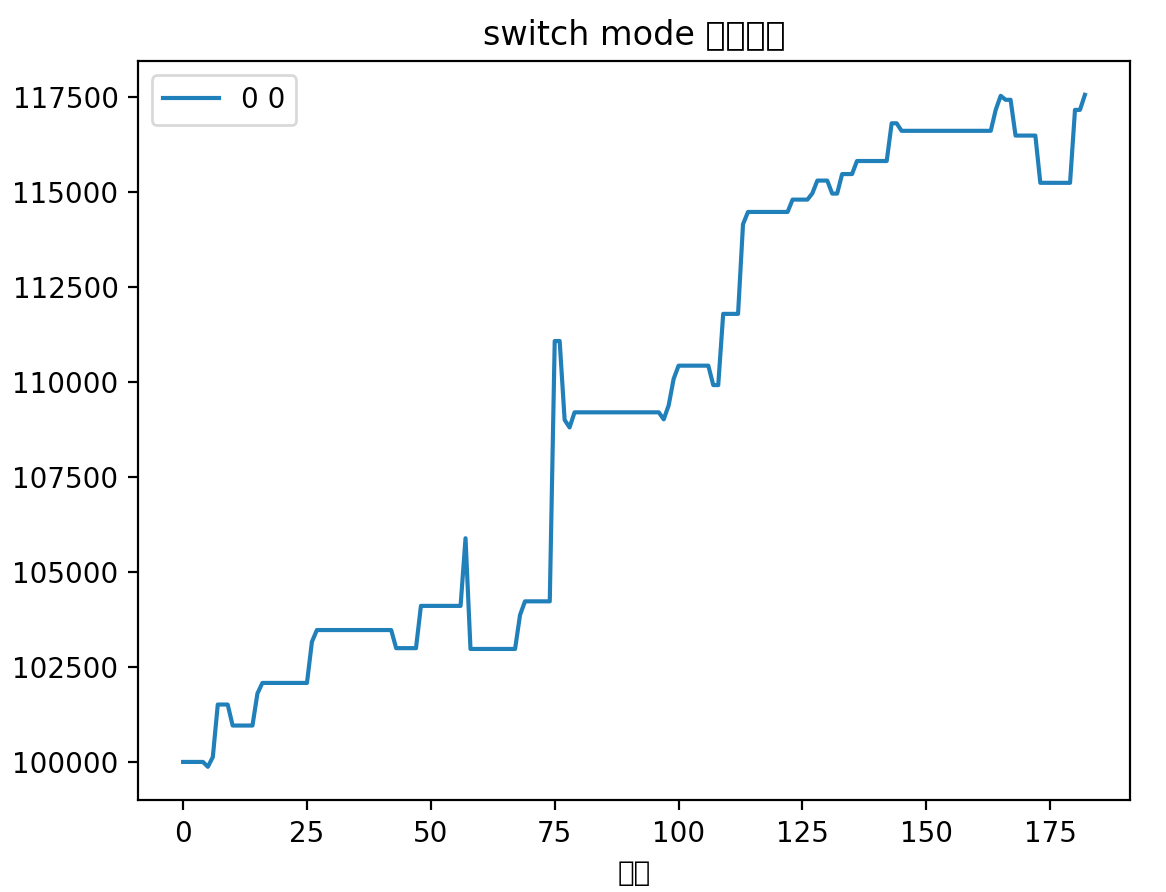
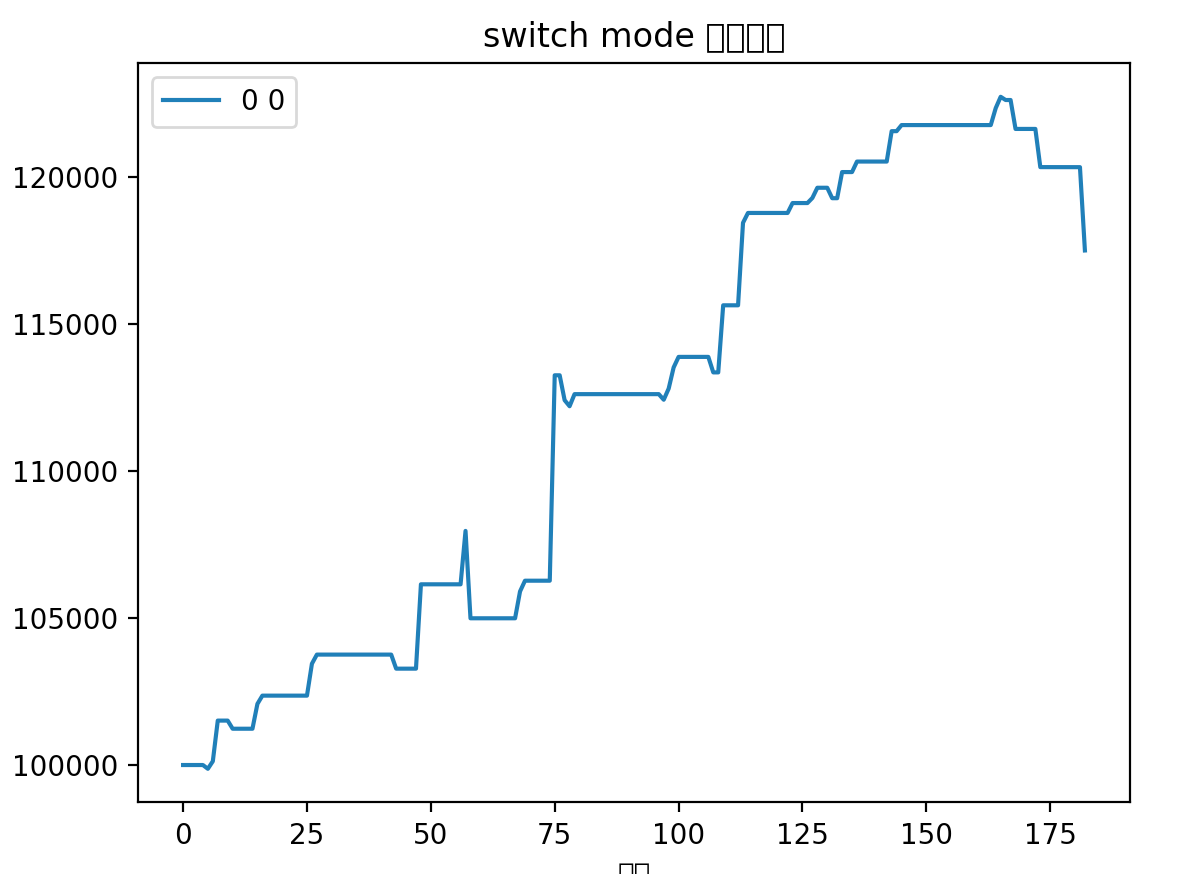
但是我发现回撤的品种全是之前定位打野的品种,然后我依稀记得之前得出过一个结论,打野基本上不赚钱,赚了亏,亏了赚,对净值只会起波动作用,而不是起增长作用。于是我便去掉打野标的进行了回撤,从2021年3月1日开始:
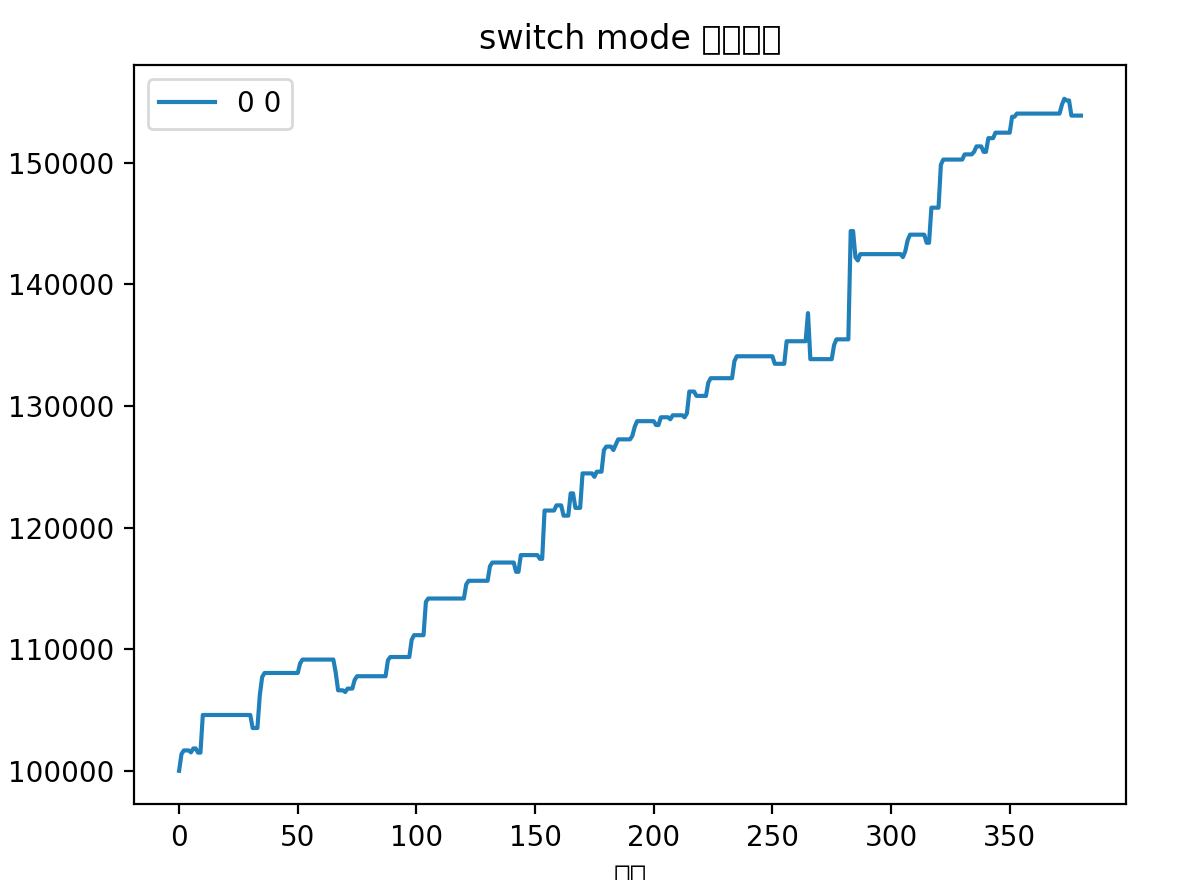
我惊呆了,标准的上楼梯曲线,一直保持东北角的上升曲线,几乎没有回撤,这不就是我追求的完美资金曲线嘛!17个月的时间,快60%的收益率,一年大概40%的收益率。
再对比下有打野标的的曲线(从2021年12月1日开始)
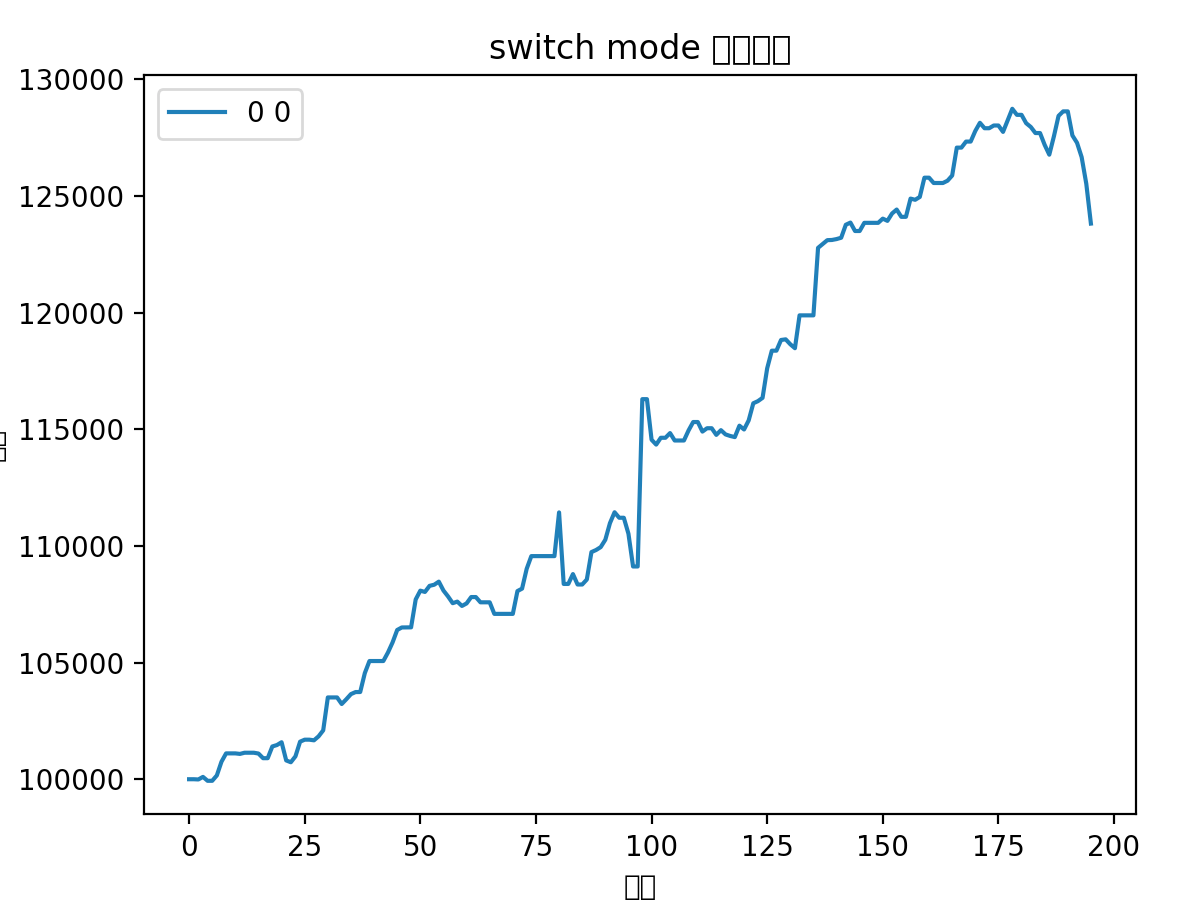
而对应的2021年12月1日开始的去除打野标的的曲线
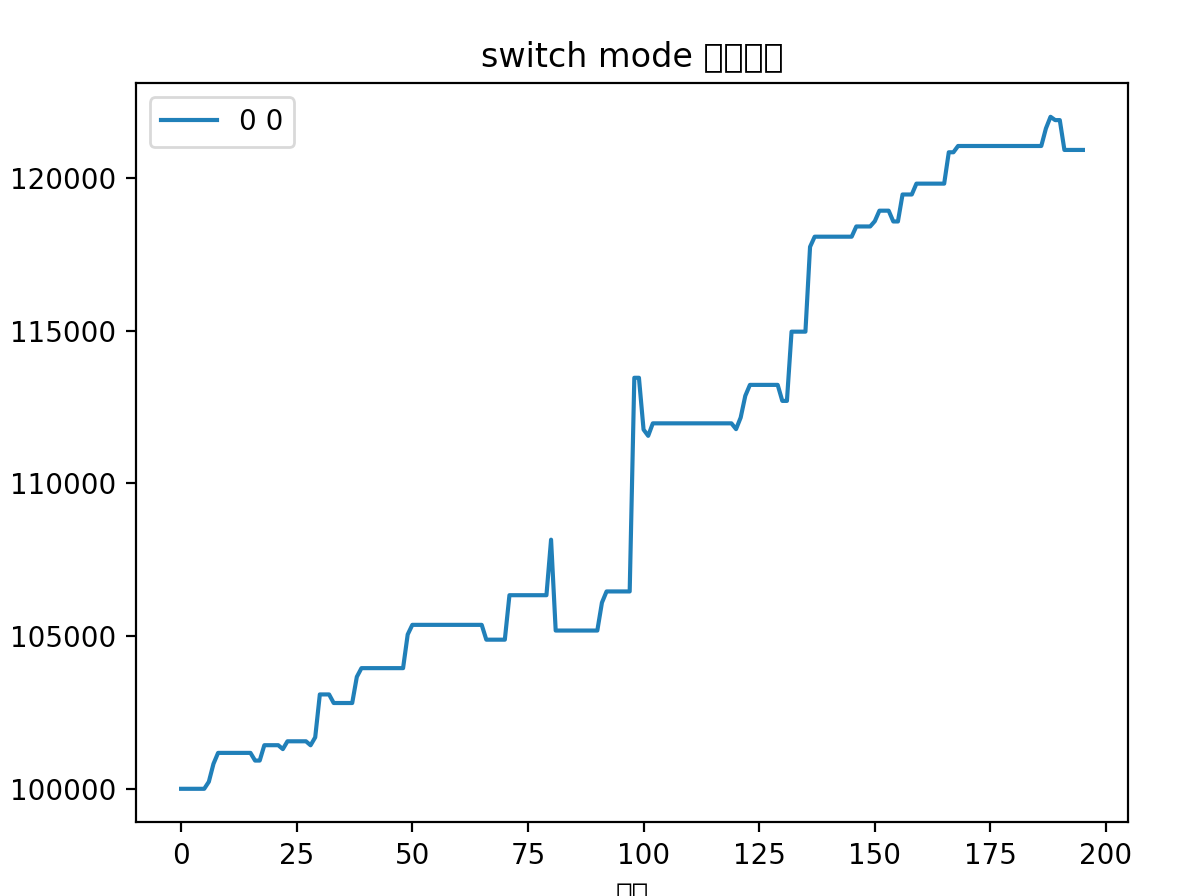
两相对比,含打野的在总收益率上略胜一筹,其实也差不多,但是不含打野的避免了大的回撤,减少了波动。最重要的是,省心省力,诸多打野来回操作也挺消耗精力,一直持仓总会不可避免的关注股市。
所以我决定,++以后FIRE基金的策略调整为不做打野标的,只做满仓标的。++
其实可以想到,如果满仓标的有回撤,那么不论采用哪种都会有回撤,而根据打野的历史经验,打野基本不赚钱,那何必劳心费神呢。
现在基金只有20%的仓位,持仓有两个打野标的,这两个又是买入后就跌,目前亏损幅度还不小,= =!。下来就是等创业板转强,梭哈就完事了。